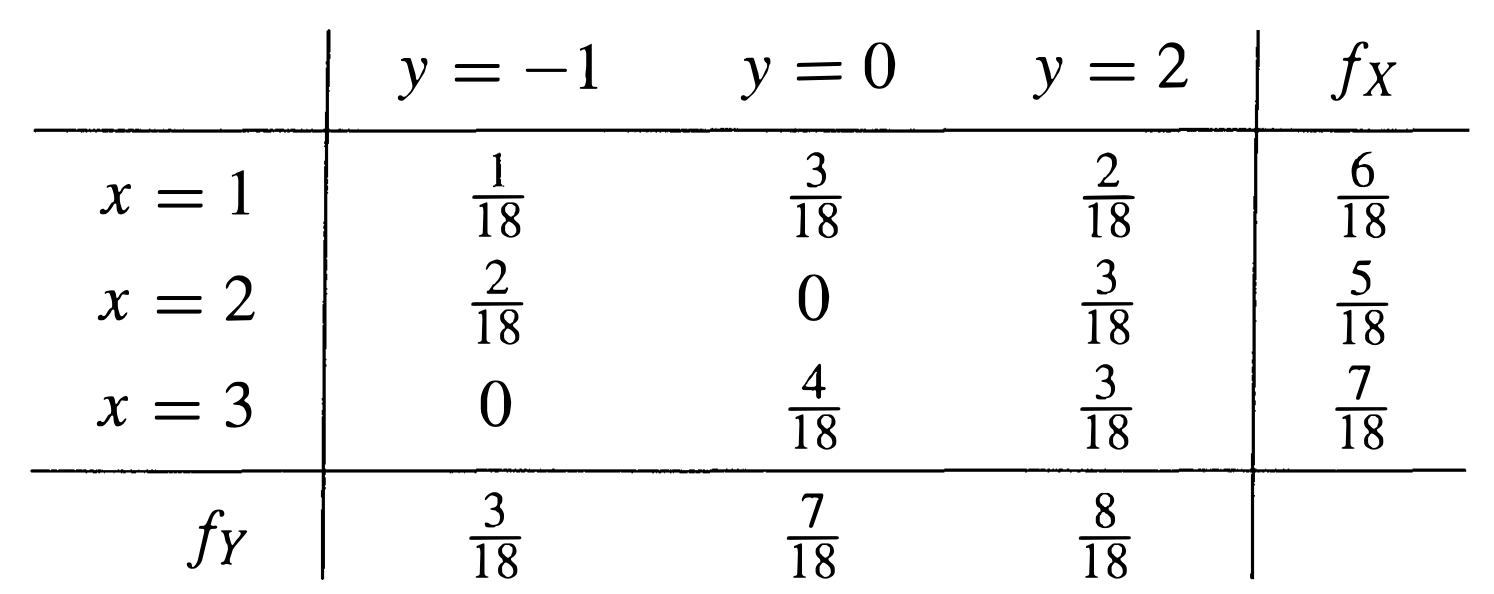第三章 离散型随机变量
我们回顾一下,离散型随机变量 X X X { x 1 , x 2 , … } \left\{x_{1}, x_{2}, \ldots\right\} { x 1 , x 2 , … } F ( x ) = P ( X ≤ x ) F(x)=\mathbb{P}(X \leq x) F ( x ) = P ( X ≤ x )
Definition 1. 离散型随机变量 X X X probability mass function(概率质量函数) f : R → [ 0 , 1 ] f: \mathbb{R} \rightarrow[0,1] f : R → [ 0 , 1 ] f ( x ) = P ( X = x ) f(x)=\mathbb{P}(X=x) f ( x ) = P ( X = x )
分布函数与质量函数间的关系为
F ( x ) = ∑ x i ≤ x f ( x i ) , f ( x ) = F ( x ) − lim y → x − F ( y ) F(x)=\sum_{x_{i} \leq x} f\left(x_{i}\right), \quad f(x)=F(x)-\lim _{y \rightarrow x^{-}} F(y) F ( x ) = x i ≤ x ∑ f ( x i ) , f ( x ) = F ( x ) − y → x − lim F ( y )
Lemma 2. 概率质量函数 f : R → [ 0 , 1 ] f: \mathbb{R} \rightarrow[0,1] f : R → [ 0 , 1 ] ∑ x ∈ R f ( x ) = 1 \sum_{x\in \mathbb{R}} f(x)=1 x ∈ R ∑ f ( x ) = 1
Example 3. Binomial distribution(二项分布). 投掷一枚硬币 n n n p p p q = 1 − p q=1-p q = 1 − p Ω = { H , T } n \Omega=\{\mathrm{H}, \mathrm{T}\}^{n} Ω = { H , T } n X ∈ { 0 , 1 , 2 , … , n } X\in \{0,1,2,\ldots,n\} X ∈ { 0 , 1 , 2 , … , n } X X X f ( x ) f(x) f ( x ) f ( x ) = 0 if x ∉ { 0 , 1 , 2 , … , n } f(x)=0 \quad \text { if } \quad x \notin\{0,1,2, \ldots, n\} f ( x ) = 0 if x ∈ / { 0 , 1 , 2 , … , n } k ∈ [ 0 , n ] k\in [0,n] k ∈ [ 0 , n ] f ( k ) = ( n k ) p k q n − k f(k)=\binom{n}{k} p^{k} q^{n-k} f ( k ) = ( k n ) p k q n − k X X X n , p n,p n , p X ∼ bin ( n , p ) X \sim \text{bin}(n,p) X ∼ bin ( n , p )
Example 4. Poisson distribution(泊松分布). 若随机变量 X ∈ { 0 , 1 , 2 , … } X\in \{0,1,2,\ldots\} X ∈ { 0 , 1 , 2 , … } f ( k ) = λ k k ! e − λ , k = 0 , 1 , 2 , … f(k)=\frac{\lambda^{k}}{k !} e^{-\lambda}, \quad k=0,1,2, \ldots f ( k ) = k ! λ k e − λ , k = 0 , 1 , 2 , … λ > 0 \lambda>0 λ > 0 X X X λ \lambda λ
Exercise 5. Log-convexity(对数凸性). f ( k − 1 ) f ( k + 1 ) ≤ f ( k ) 2 , k ≥ 1 f(k-1) f(k+1) \leq f(k)^{2},\quad k\geq 1 f ( k − 1 ) f ( k + 1 ) ≤ f ( k ) 2 , k ≥ 1 f ( k ) = 90 / ( π k ) 4 f(k)=90 /(\pi k)^{4} f ( k ) = 9 0 / ( π k ) 4 f ( k − 1 ) f ( k + 1 ) ≥ f ( k ) 2 , k ≥ 1 f(k-1) f(k+1) \geq f(k)^{2},\quad k\geq 1 f ( k − 1 ) f ( k + 1 ) ≥ f ( k ) 2 , k ≥ 1 f ( k − 1 ) f ( k + 1 ) = f ( k ) 2 , k ≥ 1 f(k-1) f(k+1) = f(k)^{2},\quad k\geq 1 f ( k − 1 ) f ( k + 1 ) = f ( k ) 2 , k ≥ 1
难度:★★★☆☆(点击查看答案) (1)对于二项分布,有
f ( k − 1 ) f ( k + 1 ) f ( k ) 2 = ( n k − 1 ) ( n k + 1 ) ( n k ) 2 = k ( n − k ) ( k + 1 ) ( n − k + 1 ) = n k − k 2 n k − k 2 + n + 1 < 1 \begin{aligned}\frac{f(k-1)f(k+1)}{f(k)^{2}}
&=\frac{\binom{n}{k-1}\binom{n}{k+1}}{\binom{n}{k}^{2}}=\frac{k(n-k)}{(k+1)(n-k+1)}\\
&=\frac{nk-k^{2}}{nk-k^{2}+n+1}<1
\end{aligned} f ( k ) 2 f ( k − 1 ) f ( k + 1 ) = ( k n ) 2 ( k − 1 n ) ( k + 1 n ) = ( k + 1 ) ( n − k + 1 ) k ( n − k ) = n k − k 2 + n + 1 n k − k 2 < 1
对于泊松分布,有
f ( k − 1 ) f ( k + 1 ) f ( k ) 2 = k k + 1 < 1 \frac{f(k-1)f(k+1)}{f(k)^{2}}=\frac{k}{k+1}<1 f ( k ) 2 f ( k − 1 ) f ( k + 1 ) = k + 1 k < 1
(2)对于给定的质量函数,有
f ( k − 1 ) f ( k + 1 ) f ( k ) 2 = k 4 ( k − 1 ) 4 ( k + 1 ) 4 = ( k 2 k 2 − 1 ) 4 > 1 \frac{f(k-1)f(k+1)}{f(k)^{2}}=\frac{k^{4}}{(k-1)^{4}(k+1)^{4}}=\left(\frac{k^{2}}{k^{2}-1}\right)^{4}>1 f ( k ) 2 f ( k − 1 ) f ( k + 1 ) = ( k − 1 ) 4 ( k + 1 ) 4 k 4 = ( k 2 − 1 k 2 ) 4 > 1
(3)我们发现需要满足的条件等价于
log f ( k − 1 ) + log f ( k + 1 ) 2 = log f ( k ) \frac{\log{f(k-1)}+\log{f(k+1)}}{2}=\log{f(k)} 2 log f ( k − 1 ) + log f ( k + 1 ) = log f ( k )
即我们的函数需要满足取对数之后,二阶导恒为零,显然取 f ( x ) = p e x f(x)=pe^{x} f ( x ) = p e x
我们之前探讨了事件间的独立性,事件 A , B A,B A , B A A A B B B
P ( A ∩ B ) = P ( A ) P ( B ) \mathbb{P}(A \cap B)=\mathbb{P}(A) \mathbb{P}(B) P ( A ∩ B ) = P ( A ) P ( B )
类似的,我们考虑离散型随机变量 X , Y X,Y X , Y X X X Y Y Y
Definition 1. 离散型随机变量 X , Y X,Y X , Y x , y x,y x , y { X = x } , { Y = y } \{X=x\},\{Y=y\} { X = x } , { Y = y }
设 X X X { x 1 , x 2 , … } \left\{x_{1}, x_{2}, \dots\right\} { x 1 , x 2 , … } Y Y Y { y 1 , y 2 , … } \left\{y_{1}, y_{2}, \ldots\right\} { y 1 , y 2 , … }
A i = { X = x i } , B j = { Y = y j } A_{i}=\left\{X=x_{i}\right\}, \quad B_{j}=\left\{Y=y_{j}\right\} A i = { X = x i } , B j = { Y = y j }
注意到 X , Y X,Y X , Y I A i , I B j I_{A_{i}},I_{B_{j}} I A i , I B j
X = ∑ i x i I A i , Y = ∑ j y j I B j X=\sum_{i} x_{i} I_{A_{i}},\quad Y=\sum_{j} y_{j} I_{B_{j}} X = i ∑ x i I A i , Y = j ∑ y j I B j
因此要使 X , Y X,Y X , Y A i , B j A_{i},B_{j} A i , B j
Example 2. Poisson flips(泊松投掷). 投掷一枚硬币,正面朝上的概率为 p = 1 − q p=1-q p = 1 − q X , Y X,Y X , Y N N N N N N λ \lambda λ X , Y X,Y X , Y
根据全概率公式,
P ( X = x ) = ∑ n ≥ x P ( X = x ∣ N = n ) P ( N = n ) = ∑ n ≥ x ( n x ) p x q n − x λ n n ! e − λ = ∑ n ≥ x λ n x ! ( n − x ) ! p x q n − x e − λ = ∑ n ≥ 0 λ n + x x ! n ! p x q n e − λ = ( λ p ) x x ! e − λ ∑ n ≥ 0 ( λ q ) n n ! = ( λ p ) x x ! e − λ e λ q = ( λ p ) x x ! e − λ p \begin{aligned}
\mathbb{P}(X=x) &=\sum_{n \geq x} \mathbb{P}(X=x | N=n) \mathbb{P}(N=n) \\
&=\sum_{n \geq x}\binom{n}{x} p^{x} q^{n-x} \frac{\lambda^{n}}{n !} e^{-\lambda}=\sum_{n\geq x}\frac{\lambda^{n}}{x!(n-x)!}p^{x}q^{n-x}e^{-\lambda}\\
&=\sum_{n\geq 0}\frac{\lambda^{n+x}}{x!n!}p^{x}q^{n}e^{-\lambda}=\frac{(\lambda p)^{x}}{x!}e^{-\lambda}\sum_{n\geq 0}\frac{(\lambda q)^{n}}{n!}\\
&=\frac{(\lambda p)^{x}}{x!}e^{-\lambda}e^{\lambda q}=\frac{(\lambda p)^{x}}{x !} e^{-\lambda p}
\end{aligned} P ( X = x ) = n ≥ x ∑ P ( X = x ∣ N = n ) P ( N = n ) = n ≥ x ∑ ( x n ) p x q n − x n ! λ n e − λ = n ≥ x ∑ x ! ( n − x ) ! λ n p x q n − x e − λ = n ≥ 0 ∑ x ! n ! λ n + x p x q n e − λ = x ! ( λ p ) x e − λ n ≥ 0 ∑ n ! ( λ q ) n = x ! ( λ p ) x e − λ e λ q = x ! ( λ p ) x e − λ p
P ( X = x , Y = y ) = P ( X = x , Y = y ∣ N = x + y ) P ( N = x + y ) = ( x + y x ) p x q y λ x + y ( x + y ) ! e − λ = ( λ p ) x ( λ q ) y x ! y ! e − λ \begin{aligned}
\mathbb{P}(X=x, Y=y) &=\mathbb{P}(X=x, Y=y | N=x+y) \mathbb{P}(N=x+y) \\
&=\binom{x+y}{x} p^{x} q^{y} \frac{\lambda^{x+y}}{(x+y) !} e^{-\lambda}=\frac{(\lambda p)^{x}(\lambda q)^{y}}{x ! y !} e^{-\lambda}
\end{aligned} P ( X = x , Y = y ) = P ( X = x , Y = y ∣ N = x + y ) P ( N = x + y ) = ( x x + y ) p x q y ( x + y ) ! λ x + y e − λ = x ! y ! ( λ p ) x ( λ q ) y e − λ
因此 X , Y X,Y X , Y
Theorem 3. 若随机变量 X , Y X,Y X , Y g , h : R → R g, h: \mathbb{R} \rightarrow \mathbb{R} g , h : R → R g ( X ) , h ( Y ) g(X),h(Y) g ( X ) , h ( Y )
证明:对于 a , b ∈ R a,b\in\mathbb{R} a , b ∈ R
P ( g ( X ) = a , h ( Y ) = b ) = ∑ g ( x ) = a , h ( y ) = b P ( X = x , Y = y ) = ∑ g ( x ) = a , h ( y ) = b P ( X = x ) P ( Y = y ) = ∑ g ( x ) = a P ( X = x ) ∑ h ( y ) = b P ( Y = y ) = P ( g ( X ) = a ) P ( h ( Y ) = b ) \begin{aligned}\mathbb{P}(g(X)=a, h(Y)=b)
&= \sum_{g(x)=a,h(y)=b} \mathbb{P}(X=x, Y=y)\\
&= \sum_{g(x)=a,h(y)=b} \mathbb{P}(X=x) \mathbb{P}(Y=y)\\
&= \sum_{g(x)=a} \mathbb{P}(X=x) \sum_{h(y)=b} \mathbb{P}(Y=y)\\
&= \mathbb{P}(g(X)=a) \mathbb{P}(h(Y)=b)
\end{aligned} P ( g ( X ) = a , h ( Y ) = b ) = g ( x ) = a , h ( y ) = b ∑ P ( X = x , Y = y ) = g ( x ) = a , h ( y ) = b ∑ P ( X = x ) P ( Y = y ) = g ( x ) = a ∑ P ( X = x ) h ( y ) = b ∑ P ( Y = y ) = P ( g ( X ) = a ) P ( h ( Y ) = b )
更一般的,我们可以把独立性推广到多个随机变量,即一组离散型随机变量 { X i ∣ i ∈ I } \left\{X_{i}\mid i \in I\right\} { X i ∣ i ∈ I } { X i = x i } \left\{X_{i}=x_{i}\right\} { X i = x i } X i X_{i} X i x i x_{i} x i
Exercise 4. 设随机变量 X , Y ∈ Z + X,Y\in \mathbb{Z}^{+} X , Y ∈ Z + f ( x ) = 2 − x f(x)=2^{-x} f ( x ) = 2 − x P ( min { X , Y } ≤ x ) \mathbb{P}(\min \{X, Y\} \leq x) P ( min { X , Y } ≤ x ) x ≥ 1 x\geq 1 x ≥ 1 P ( X < Y ) \mathbb{P}(X<Y) P ( X < Y ) P ( X divides Y ) \mathbb{P}(X \text { divides } Y) P ( X divides Y ) P ( X ≥ k Y ) \mathbb{P}(X \geq k Y) P ( X ≥ k Y ) k k k P ( X = r Y ) \mathbb{P}(X=r Y) P ( X = r Y ) r r r
难度:★★☆☆☆(点击查看答案)
P ( min { X , Y } ≤ x ) = 1 − P ( X > x , Y > x ) = 1 − P ( X > x ) P ( Y > x ) = 1 − 2 − x ⋅ 2 − x = 1 − 4 − x P ( X < Y ) = ∑ x = 1 ∞ ∑ y = x + 1 ∞ P ( X = x , Y = y ) = ∑ x = 1 ∞ ∑ y = x + 1 ∞ 2 − x ⋅ 2 − y = 1 3 P ( X divides Y ) = ∑ k = 1 ∞ P ( Y = k X ) = ∑ k = 1 ∞ ∑ x = 1 ∞ P ( Y = k x , X = x ) = ∑ k = 1 ∞ ∑ x = 1 ∞ 2 − k x 2 − x = ∑ k = 1 ∞ 1 2 k + 1 − 1 P ( X ≥ k Y ) = ∑ y = 1 ∞ P ( X ≥ k y , Y = y ) = ∑ y = 1 ∞ P ( X ≥ k y ) P ( Y = y ) = ∑ y = 1 ∞ ∑ x = 0 ∞ 2 − k y − x 2 − y = 2 2 k + 1 − 1 P ( X = r Y ) = ∑ k = 1 ∞ P ( X = k m , Y = k n ) ( r 的最简分数形式为 m n ) = ∑ k = 1 ∞ 2 − k m 2 − k n = 1 2 m + n − 1 \begin{aligned}
\mathbb{P}(\min \{X, Y\} \leq x) &=1-\mathbb{P}(X>x, Y>x)=1-\mathbb{P}(X>x) \mathbb{P}(Y>x) \\
&=1-2^{-x} \cdot 2^{-x}=1-4^{-x}\\
\mathbb{P}(X<Y)&=\sum_{x=1}^{\infty}\sum_{y=x+1}^{\infty}\mathbb{P}(X=x,Y=y)\\
&=\sum_{x=1}^{\infty}\sum_{y=x+1}^{\infty}2^{-x}\cdot 2^{-y}=\frac{1}{3}\\
\mathbb{P}(X \text { divides } Y) &=\sum_{k=1}^{\infty} \mathbb{P}(Y=k X)=\sum_{k=1}^{\infty} \sum_{x=1}^{\infty} \mathbb{P}(Y=k x, X=x) \\
&=\sum_{k=1}^{\infty} \sum_{x=1}^{\infty} 2^{-k x} 2^{-x}=\sum_{k=1}^{\infty} \frac{1}{2^{k+1}-1}\\
\mathbb{P}(X \geq k Y) &=\sum_{y=1}^{\infty} \mathbb{P}(X \geq k y, Y=y)=\sum_{y=1}^{\infty} \mathbb{P}(X \geq k y) \mathbb{P}(Y=y) \\
&=\sum_{y=1}^{\infty} \sum_{x=0}^{\infty} 2^{-k y-x} 2^{-y}=\frac{2}{2^{k+1}-1}\\
\mathbb{P}(X=r Y)&=\sum_{k=1}^{\infty} \mathbb{P}(X=k m, Y=k n)(r \text{ 的最简分数形式为 } \frac{m}{n})\\
&=\sum_{k=1}^{\infty} 2^{-k m} 2^{-k n}=\frac{1}{2^{m+n}-1}
\end{aligned} P ( min { X , Y } ≤ x ) P ( X < Y ) P ( X divides Y ) P ( X ≥ k Y ) P ( X = r Y ) = 1 − P ( X > x , Y > x ) = 1 − P ( X > x ) P ( Y > x ) = 1 − 2 − x ⋅ 2 − x = 1 − 4 − x = x = 1 ∑ ∞ y = x + 1 ∑ ∞ P ( X = x , Y = y ) = x = 1 ∑ ∞ y = x + 1 ∑ ∞ 2 − x ⋅ 2 − y = 3 1 = k = 1 ∑ ∞ P ( Y = k X ) = k = 1 ∑ ∞ x = 1 ∑ ∞ P ( Y = k x , X = x ) = k = 1 ∑ ∞ x = 1 ∑ ∞ 2 − k x 2 − x = k = 1 ∑ ∞ 2 k + 1 − 1 1 = y = 1 ∑ ∞ P ( X ≥ k y , Y = y ) = y = 1 ∑ ∞ P ( X ≥ k y ) P ( Y = y ) = y = 1 ∑ ∞ x = 0 ∑ ∞ 2 − k y − x 2 − y = 2 k + 1 − 1 2 = k = 1 ∑ ∞ P ( X = k m , Y = k n ) ( r 的最简分数形式为 n m ) = k = 1 ∑ ∞ 2 − k m 2 − k n = 2 m + n − 1 1
Exercise 5. 三个玩家 A , B , C A,B,C A , B , C A B C A B C … ABCABC\ldots A B C A B C … 6 6 6 A A A B B B C C C 216 1001 \frac{216}{1001} 1 0 0 1 2 1 6 6 6 6 A A A B B B C C C 46656 753571 \frac{46656}{753571} 7 5 3 5 7 1 4 6 6 5 6
难度:★★★★☆(点击查看答案) (1)设事件 { A < B < C } \{A<B<C\} { A < B < C } A A A B B B 6 6 6 B B B C C C 6 6 6
本轮中 A , B A,B A , B 6 6 6
本轮中 A A A 6 6 6 B , C B,C B , C { B < C } \{B<C\} { B < C }
本轮中没有人扔出 6 6 6 { A < B < C } \{A<B<C\} { A < B < C }
事件 { B < C } \{B<C\} { B < C }
P ( A < B < C ) = ( 1 6 ) 2 + 1 6 ( 5 6 ) 2 P ( B < C ) + ( 5 6 ) 3 P ( A < B < C ) \mathbb{P}(A<B<C)=\left(\frac{1}{6}\right)^{2}+\frac{1}{6}\left(\frac{5}{6}\right)^{2} \mathbb{P}(B<C)+\left(\frac{5}{6}\right)^{3} \mathbb{P}(A<B<C) P ( A < B < C ) = ( 6 1 ) 2 + 6 1 ( 6 5 ) 2 P ( B < C ) + ( 6 5 ) 3 P ( A < B < C )
P ( B < C ) = ( 5 6 ) 2 P ( B < C ) + 1 6 \mathbb{P}(B<C)=\left(\frac{5}{6}\right)^{2} \mathbb{P}(B<C)+\frac{1}{6} P ( B < C ) = ( 6 5 ) 2 P ( B < C ) + 6 1
据此我们得到 P ( B < C ) = 6 11 \mathbb{P}(B<C)=\frac{6}{11} P ( B < C ) = 1 1 6 P ( A < B < C ) = 216 1001 \mathbb{P}(A<B<C)=\frac{216}{1001} P ( A < B < C ) = 1 0 0 1 2 1 6
(2)设 N N N 6 6 6 6 6 6 A A A N ∈ { 1 , 4 , 7 , … } N\in \{1,4,7,\ldots\} N ∈ { 1 , 4 , 7 , … }
P ( N ∈ { 1 , 4 , 7 , … } ) = ∑ k = 1 , 4 , 7 , … ( 5 6 ) k − 1 1 6 = 36 91 \mathbb{P}(N \in\{1,4,7, \ldots\})=\sum_{k=1,4,7, \ldots}\left(\frac{5}{6}\right)^{k-1} \frac{1}{6}=\frac{36}{91} P ( N ∈ { 1 , 4 , 7 , … } ) = k = 1 , 4 , 7 , … ∑ ( 6 5 ) k − 1 6 1 = 9 1 3 6
当 A A A 6 6 6 B C A B C A … BCABCA\ldots B C A B C A … 6 6 6 B B B
A n s = ( 36 91 ) 3 = 46656 753571 Ans=\left(\frac{36}{91}\right)^{3}=\frac{46656}{753571} A n s = ( 9 1 3 6 ) 3 = 7 5 3 5 7 1 4 6 6 5 6
设 x 1 , x 2 , … , x N x_{1}, x_{2}, \ldots, x_{N} x 1 , x 2 , … , x N N N N
m = 1 N ∑ i x i m=\frac{1}{N} \sum_{i} x_{i} m = N 1 i ∑ x i
现在,我们设随机变量 X 1 , X 2 , … , X N X_{1}, X_{2}, \ldots, X_{N} X 1 , X 2 , … , X N N N N f f f x x x N f ( x ) Nf(x) N f ( x ) X i X_{i} X i x x x
m ≈ 1 N ∑ x x N f ( x ) = ∑ x x f ( x ) m \approx \frac{1}{N} \sum_{x} x N f(x)=\sum_{x} x f(x) m ≈ N 1 x ∑ x N f ( x ) = x ∑ x f ( x )
这个均值 m m m f f f expectation(期望) 或 mean value(均值) .
Definition 1. 随机变量 X X X E ( X ) = ∑ x x f ( x ) \mathbb{E}(X)=\sum_{x} x f(x) E ( X ) = x ∑ x f ( x ) f f f
我们要求右边的和式绝对收敛,这是为了保证交换 x i x_{i} x i
想象一下,我们把 X X X x x x f ( x ) f(x) f ( x ) X X X
Example 2. 我们回到 Example 2.1.1 中的例子,随机变量 X , W X,W X , W E ( X ) = ∑ x x P ( X = x ) = 0 ⋅ 1 4 + 1 ⋅ 1 2 + 2 ⋅ 1 4 = 1 E ( W ) = ∑ x x P ( W = x ) = 0 ⋅ 3 4 + 4 ⋅ 1 4 = 1 \begin{aligned}
\mathbb{E}(X)&=\sum_{x} x \mathbb{P}(X=x)=0 \cdot \frac{1}{4}+1 \cdot \frac{1}{2}+2 \cdot \frac{1}{4}=1 \\
\mathbb{E}(W)&=\sum_{x} x \mathbb{P}(W=x)=0 \cdot \frac{3}{4}+4 \cdot \frac{1}{4}=1
\end{aligned} E ( X ) E ( W ) = x ∑ x P ( X = x ) = 0 ⋅ 4 1 + 1 ⋅ 2 1 + 2 ⋅ 4 1 = 1 = x ∑ x P ( W = x ) = 0 ⋅ 4 3 + 4 ⋅ 4 1 = 1
若 X X X g : R → R g: \mathbb{R} \rightarrow \mathbb{R} g : R → R Y = g ( X ) Y=g(X) Y = g ( X ) Y ( ω ) = g ( X ( ω ) ) Y(\omega)=g(X(\omega)) Y ( ω ) = g ( X ( ω ) ) Y Y Y Y Y Y
按照定义,我们必须先求出 Y Y Y f Y f_{Y} f Y
Lemma 3. 若随机变量 X X X f f f g : R → R g: \mathbb{R} \rightarrow \mathbb{R} g : R → R E ( g ( X ) ) = ∑ x g ( x ) f ( x ) \mathbb{E}(g(X))=\sum_{x} g(x) f(x) E ( g ( X ) ) = x ∑ g ( x ) f ( x )
证明如下:(亮点在于最后一步中的交换求和号)
E ( g ( X ) ) = ∑ y y P ( g ( X ) = y ) = ∑ y ∑ x : g ( x ) = y y P ( X = x ) = ∑ x g ( x ) P ( X = x ) \begin{aligned}\mathbb{E}(g(X))
&=\sum_{y} y \mathbb{P}(g(X)=y)=\sum_{y} \sum_{x: g(x)=y} y \mathbb{P}(X=x)\\
&=\sum_{x} g(x) \mathbb{P}(X=x)
\end{aligned} E ( g ( X ) ) = y ∑ y P ( g ( X ) = y ) = y ∑ x : g ( x ) = y ∑ y P ( X = x ) = x ∑ g ( x ) P ( X = x )
这个引理被称为 law of the unconscious statisitician(无意识统计学家法则) .
Example 4. 设随机变量 X X X − 2 , − 1 , 1 , 3 -2,-1,1,3 − 2 , − 1 , 1 , 3 1 4 , 1 8 , 1 4 , 3 8 \frac{1}{4}, \frac{1}{8}, \frac{1}{4}, \frac{3}{8} 4 1 , 8 1 , 4 1 , 8 3 Y = X 2 Y=X^{2} Y = X 2
我们用这个例子直观的检验一下上面的引理,按照常规流程来做,Y Y Y 1 , 4 , 9 1,4,9 1 , 4 , 9 3 8 , 1 4 , 3 8 \frac{3}{8}, \frac{1}{4}, \frac{3}{8} 8 3 , 4 1 , 8 3
E ( Y ) = ∑ x x P ( Y = x ) = 1 ⋅ 3 8 + 4 ⋅ 1 4 + 9 ⋅ 3 8 = 19 4 \mathbb{E}(Y)=\sum_{x} x \mathbb{P}(Y=x)=1 \cdot \frac{3}{8}+4 \cdot \frac{1}{4}+9 \cdot \frac{3}{8}=\frac{19}{4} E ( Y ) = x ∑ x P ( Y = x ) = 1 ⋅ 8 3 + 4 ⋅ 4 1 + 9 ⋅ 8 3 = 4 1 9
而如果直接使用引理
E ( Y ) = ∑ x x 2 P ( X = x ) = 4 ⋅ 1 4 + 1 ⋅ 1 8 + 1 ⋅ 1 4 + 9 ⋅ 3 8 = 19 4 \mathbb{E}(Y)=\sum_{x} x^{2} \mathbb{P}(X=x)=4 \cdot \frac{1}{4}+1 \cdot \frac{1}{8}+1 \cdot \frac{1}{4}+9 \cdot \frac{3}{8}=\frac{19}{4} E ( Y ) = x ∑ x 2 P ( X = x ) = 4 ⋅ 4 1 + 1 ⋅ 8 1 + 1 ⋅ 4 1 + 9 ⋅ 8 3 = 4 1 9
Definition 5. 若 k k k X X X k-th moment(k阶矩) m k m_{k} m k m k = E ( X k ) m_{k}=\mathbb{E}\left(X^{k}\right) m k = E ( X k ) X X X k-th central moment(k阶中心矩) σ k \sigma_{k} σ k σ k = E ( ( X − m 1 ) k ) \sigma_{k}=\mathbb{E}\left(\left(X-m_{1}\right)^{k}\right) σ k = E ( ( X − m 1 ) k )
我们最常使用的两个矩是
m 1 = E ( X ) , σ 2 = E ( ( X − E X ) 2 ) m_{1}=\mathbb{E}(X),\quad \sigma_{2}=\mathbb{E}\left((X-\mathbb{E} X)^{2}\right) m 1 = E ( X ) , σ 2 = E ( ( X − E X ) 2 )
分别叫做 X X X expectation(期望) 和 variance(方差) ,这两个量分别描述了 X X X
我们常把 m 1 m_{1} m 1 μ \mu μ var ( X ) \operatorname{var}(X) v a r ( X ) σ = var ( X ) \sigma=\sqrt{\operatorname{var}(X)} σ = v a r ( X ) standard deviation(标准偏差) .
注:根据定义,显然 var ( X ) \operatorname{var}(X) v a r ( X )
事实上中心矩 { σ i } \{\sigma_{i}\} { σ i } { m i } \{m_{i}\} { m i }
σ 2 = ∑ x ( x − m 1 ) 2 f ( x ) = ∑ x x 2 f ( x ) − 2 m 1 ∑ x x f ( x ) + m 1 2 ∑ x f ( x ) = m 2 − m 1 2 \begin{aligned}
\sigma_{2} &=\sum_{x}\left(x-m_{1}\right)^{2} f(x) \\
&=\sum_{x} x^{2} f(x)-2 m_{1} \sum_{x} x f(x)+m_{1}^{2} \sum_{x} f(x) \\
&=m_{2}-m_{1}^{2}
\end{aligned} σ 2 = x ∑ ( x − m 1 ) 2 f ( x ) = x ∑ x 2 f ( x ) − 2 m 1 x ∑ x f ( x ) + m 1 2 x ∑ f ( x ) = m 2 − m 1 2
该式即是普遍使用的方差计算式
var ( X ) = E ( ( X − E X ) 2 ) = E ( X 2 ) − ( E X ) 2 \operatorname{var}(X)=\mathbb{E}\left((X-\mathbb{E} X)^{2}\right)=\mathbb{E}\left(X^{2}\right)-(\mathbb{E} X)^{2} v a r ( X ) = E ( ( X − E X ) 2 ) = E ( X 2 ) − ( E X ) 2
Example 6. Bernoulli distribution(伯努利分布). 设 X X X 1 1 1 p = 1 − q p=1-q p = 1 − q E ( X ) = ∑ x x f ( x ) = 0 ⋅ q + 1 ⋅ p = p E ( X 2 ) = ∑ x x 2 f ( x ) = 0 ⋅ q + 1 ⋅ p = p var ( X ) = E ( X 2 ) − E ( X ) 2 = p q \begin{aligned}
\mathbb{E}(X) &=\sum_{x} x f(x)=0 \cdot q+1 \cdot p=p \\
\mathbb{E}\left(X^{2}\right) &=\sum_{x} x^{2} f(x)=0 \cdot q+1 \cdot p=p \\
\operatorname{var}(X) &=\mathbb{E}\left(X^{2}\right)-\mathbb{E}(X)^{2}=p q
\end{aligned} E ( X ) E ( X 2 ) v a r ( X ) = x ∑ x f ( x ) = 0 ⋅ q + 1 ⋅ p = p = x ∑ x 2 f ( x ) = 0 ⋅ q + 1 ⋅ p = p = E ( X 2 ) − E ( X ) 2 = p q
Example 7. Binomial distribution(二项分布). 设 X ∼ bin ( n , p ) X\sim \text{bin}(n,p) X ∼ bin ( n , p ) E ( X ) = ∑ k = 0 n k f ( k ) = ∑ k = 0 n k ( n k ) p k q n − k \mathbb{E}(X)=\sum_{k=0}^{n} k f(k)=\sum_{k=0}^{n} k\binom{n}{k} p^{k} q^{n-k} E ( X ) = k = 0 ∑ n k f ( k ) = k = 0 ∑ n k ( k n ) p k q n − k ∑ k = 0 n ( n k ) x k = ( 1 + x ) n \sum_{k=0}^{n}\binom{n}{k} x^{k}=(1+x)^{n} k = 0 ∑ n ( k n ) x k = ( 1 + x ) n x x x ∑ k = 0 n k ( n k ) x k = n x ( 1 + x ) n − 1 \sum_{k=0}^{n} k\binom{n}{k} x^{k}=n x(1+x)^{n-1} k = 0 ∑ n k ( k n ) x k = n x ( 1 + x ) n − 1 x = p / q x=p/q x = p / q E ( X ) = n q n p q ( 1 + p q ) n − 1 = n p \mathbb{E}(X)=nq^{n}\frac{p}{q}(1+\frac{p}{q})^{n-1}=np E ( X ) = n q n q p ( 1 + q p ) n − 1 = n p var ( X ) = n p q \operatorname{var}(X)=n p q v a r ( X ) = n p q
Theorem 8. 期望算子 E \mathbb{E} E a , b ∈ R a, b \in \mathbb{R} a , b ∈ R E ( a X + b Y ) = a E ( X ) + b E ( Y ) \mathbb{E}(a X+b Y)=a \mathbb{E}(X)+b \mathbb{E}(Y) E ( a X + b Y ) = a E ( X ) + b E ( Y )
证明:设事件 A x = { X = x } , B y = { Y = y } A_{x}=\{X=x\}, B_{y}=\{Y=y\} A x = { X = x } , B y = { Y = y }
E ( a X + b Y ) = ∑ x , y ( a x + b y ) P ( A x ∩ B y ) = ∑ x a x ∑ y P ( A x ∩ B y ) + ∑ y b y ∑ x P ( A x ∩ B y ) \begin{aligned}\mathbb{E}(a X+b Y)
&=\sum_{x, y}(a x+b y) \mathbb{P}\left(A_{x} \cap B_{y}\right)\\
&=\sum_{x}a x \sum_{y}\mathbb{P}\left(A_{x} \cap B_{y}\right)+\sum_{y}b y\sum_{x}\mathbb{P}\left(A_{x} \cap B_{y}\right)
\end{aligned} E ( a X + b Y ) = x , y ∑ ( a x + b y ) P ( A x ∩ B y ) = x ∑ a x y ∑ P ( A x ∩ B y ) + y ∑ b y x ∑ P ( A x ∩ B y )
我们发现需要解决两个部分:
∑ y P ( A x ∩ B y ) = P ( A x ∩ ( ⋃ y B y ) ) = P ( A x ∩ Ω ) = P ( A x ) \sum_{y} \mathbb{P}\left(A_{x} \cap B_{y}\right)=\mathbb{P}\left(A_{x} \cap\left(\bigcup_{y} B_{y}\right)\right)=\mathbb{P}\left(A_{x} \cap \Omega\right)=\mathbb{P}\left(A_{x}\right) y ∑ P ( A x ∩ B y ) = P ( A x ∩ ( y ⋃ B y ) ) = P ( A x ∩ Ω ) = P ( A x )
∑ x P ( A x ∩ B y ) = P ( ( ⋃ x A x ) ∩ B y ) = P ( Ω ∩ B y ) = P ( B y ) \sum_{x} \mathbb{P}\left(A_{x} \cap B_{y}\right)=\mathbb{P}\left(\left(\bigcup_{x} A_{x} \right)\cap B_{y}\right)=\mathbb{P}\left(\Omega \cap B_{y}\right)=\mathbb{P}\left(B_{y}\right) x ∑ P ( A x ∩ B y ) = P ( ( x ⋃ A x ) ∩ B y ) = P ( Ω ∩ B y ) = P ( B y )
带入得到
E ( a X + b Y ) = a ∑ x x P ( A x ) + b ∑ y y P ( B y ) = a E ( X ) + b E ( Y ) \begin{aligned}\mathbb{E}(a X+b Y)
&=a \sum_{x} x \mathbb{P}\left(A_{x}\right)+b \sum_{y} y \mathbb{P}\left(B_{y}\right) \\
&=a \mathbb{E}(X)+b \mathbb{E}(Y)
\end{aligned} E ( a X + b Y ) = a x ∑ x P ( A x ) + b y ∑ y P ( B y ) = a E ( X ) + b E ( Y )
我们证明了期望的线性性质,但遗憾的是 E ( X Y ) = E ( X ) E ( Y ) \mathbb{E}(X Y)=\mathbb{E}(X) \mathbb{E}(Y) E ( X Y ) = E ( X ) E ( Y )
Theorem 9. 若随机变量 X , Y X,Y X , Y E ( X Y ) = E ( X ) E ( Y ) \mathbb{E}(X Y)=\mathbb{E}(X) \mathbb{E}(Y) E ( X Y ) = E ( X ) E ( Y )
证明:设事件 A x = { X = x } , B y = { Y = y } A_{x}=\{X=x\}, B_{y}=\{Y=y\} A x = { X = x } , B y = { Y = y }
E ( X Y ) = ∑ x , y x y P ( A x ) P ( B y ) by independence = ∑ x P ( A x ) ∑ y P ( B y ) = E ( X ) E ( Y ) \begin{aligned}
\mathbb{E}(X Y) &=\sum_{x, y} x y \mathbb{P}\left(A_{x}\right) \mathbb{P}\left(B_{y}\right) \quad \text { by independence } \\
&=\sum x \mathbb{P}\left(A_{x}\right) \sum y \mathbb{P}\left(B_{y}\right)=\mathbb{E}(X) \mathbb{E}(Y)
\end{aligned} E ( X Y ) = x , y ∑ x y P ( A x ) P ( B y ) by independence = ∑ x P ( A x ) ∑ y P ( B y ) = E ( X ) E ( Y )
若随机变量 X , Y X,Y X , Y E ( X Y ) = E ( X ) E ( Y ) \mathbb{E}(X Y)=\mathbb{E}(X) \mathbb{E}(Y) E ( X Y ) = E ( X ) E ( Y ) X , Y X,Y X , Y uncorrelated(不相关) .
上面的定理告诉我们独立的随机变量一定不相关,但是反过来却不一定成立。
Example 10. 设 X , Y X,Y X , Y 1 2 \frac{1}{2} 2 1 X + Y , ∣ X − Y ∣ X+Y, \quad |X-Y| X + Y , ∣ X − Y ∣
E { ( X + Y ) ∣ X − Y ∣ } = 1 4 ( 0 + 1 + 1 + 0 ) = 1 2 E ( X + Y ) E ( ∣ X − Y ∣ ) = 1 4 ( 0 + 1 + 1 + 2 ) × 1 4 ( 0 + 1 + 1 + 0 ) = 1 2 P ( X + Y = 0 , ∣ X − Y ∣ = 0 ) = P ( X = 0 , Y = 0 ) = 1 4 P ( X + Y = 0 ) P ( ∣ X − Y ∣ = 0 ) = P 2 ( X = 0 , Y = 0 ) P ( X = 1 , Y = 1 ) = 1 8 \begin{aligned}
\mathbb{E}\{(X+Y)|X-Y|\}&=\frac{1}{4}(0+1+1+0)=\frac{1}{2}\\
\mathbb{E}(X+Y) \mathbb{E}(|X-Y|)&=\frac{1}{4}(0+1+1+2)\times \frac{1}{4}(0+1+1+0)=\frac{1}{2}\\
\mathbb{P}(X+Y=0,|X-Y|=0)&=\mathbb{P}(X=0,Y=0)=\frac{1}{4}\\
\mathbb{P}(X+Y=0) \mathbb{P}(|X-Y|=0)&=\mathbb{P}^{2}(X=0,Y=0)\mathbb{P}(X=1,Y=1)=\frac{1}{8}
\end{aligned} E { ( X + Y ) ∣ X − Y ∣ } E ( X + Y ) E ( ∣ X − Y ∣ ) P ( X + Y = 0 , ∣ X − Y ∣ = 0 ) P ( X + Y = 0 ) P ( ∣ X − Y ∣ = 0 ) = 4 1 ( 0 + 1 + 1 + 0 ) = 2 1 = 4 1 ( 0 + 1 + 1 + 2 ) × 4 1 ( 0 + 1 + 1 + 0 ) = 2 1 = P ( X = 0 , Y = 0 ) = 4 1 = P 2 ( X = 0 , Y = 0 ) P ( X = 1 , Y = 1 ) = 8 1
Theorem 11. 随机变量 X , Y X,Y X , Y var ( a X ) = a 2 var ( X ) \operatorname{var}(a X)=a^{2} \operatorname{var}(X) v a r ( a X ) = a 2 v a r ( X ) a ∈ R a\in \mathbb{R} a ∈ R var ( X + Y ) = var ( X ) + var ( Y ) \operatorname{var}(X+Y)=\operatorname{var}(X)+\operatorname{var}(Y) v a r ( X + Y ) = v a r ( X ) + v a r ( Y ) X , Y X,Y X , Y
证明:(1)根据期望的线性性质
var ( a X ) = E { ( a X − E ( a X ) ) 2 } = E { a 2 ( X − E X ) 2 } = a 2 E { ( X − E X ) 2 } = a 2 var ( X ) \begin{aligned}
\operatorname{var}(a X) &=\mathbb{E}\left\{(a X-\mathbb{E}(a X))^{2}\right\}=\mathbb{E}\left\{a^{2}(X-\mathbb{E} X)^{2}\right\} \\
&=a^{2} \mathbb{E}\left\{(X-\mathbb{E} X)^{2}\right\}=a^{2} \operatorname{var}(X)
\end{aligned} v a r ( a X ) = E { ( a X − E ( a X ) ) 2 } = E { a 2 ( X − E X ) 2 } = a 2 E { ( X − E X ) 2 } = a 2 v a r ( X )
(2)根据 X , Y X,Y X , Y
var ( X + Y ) = E { ( X + Y − E ( X + Y ) ) 2 } = E [ ( X − E X ) 2 + 2 ( X Y − E ( X ) E ( Y ) ) + ( Y − E Y ) 2 ] = var ( X ) + 2 [ E ( X Y ) − E ( X ) E ( Y ) ] + var ( Y ) = var ( X ) + var ( Y ) \begin{aligned}
\operatorname{var}(X+Y) &=\mathbb{E}\left\{(X+Y-\mathbb{E}(X+Y))^{2}\right\} \\
&=\mathbb{E}\left[(X-\mathbb{E} X)^{2}+2(X Y-\mathbb{E}(X) \mathbb{E}(Y))+(Y-\mathbb{E} Y)^{2}\right] \\
&=\operatorname{var}(X)+2[\mathbb{E}(X Y)-\mathbb{E}(X) \mathbb{E}(Y)]+\operatorname{var}(Y) \\
&=\operatorname{var}(X)+\operatorname{var}(Y)
\end{aligned} v a r ( X + Y ) = E { ( X + Y − E ( X + Y ) ) 2 } = E [ ( X − E X ) 2 + 2 ( X Y − E ( X ) E ( Y ) ) + ( Y − E Y ) 2 ] = v a r ( X ) + 2 [ E ( X Y ) − E ( X ) E ( Y ) ] + v a r ( Y ) = v a r ( X ) + v a r ( Y )
在某些情况下,级数 S = ∑ x f ( x ) S=\sum x f(x) S = ∑ x f ( x ) f ( x ) f(x) f ( x )
Example 12. A distribution without a mean(不存在期望的分布). 设随机变量 X X X f ( k ) = A k − 2 for k = ± 1 , ± 2 , … f(k)=A k^{-2} \quad \text { for } \quad k=\pm 1,\pm 2, \ldots f ( k ) = A k − 2 for k = ± 1 , ± 2 , … A A A ∑ f ( k ) = 1 \sum f(k)=1 ∑ f ( k ) = 1 ∑ k k f ( k ) = A ∑ k ≠ 0 k − 1 \sum_{k} k f(k)=A \sum_{k \neq 0} k^{-1} k ∑ k f ( k ) = A k = 0 ∑ k − 1
值得一提的是,现在我们可以将概率论的根基建立在期望算子 E \mathbb{E} E P \mathbb{P} P average 的直觉已经和量化的概率一样好了。
严谨来说,我们以 Theorem 8 为公理定义了名为 expectation operator(期望算子) 的东西,作用于随机变量所在的空间,而事件发生的概率可以重新定义为
P ( A ) = E ( I A ) \mathbb{P}(A)=\mathbb{E}\left(I_{A}\right) P ( A ) = E ( I A )
Whittle 曾是该理论的有力支持者,著有《Probability via Expectation 》.
这样的理论可用于解决 quantum theory(量子理论) 中的概率学问题,量子理论是理论物理学的一个重要分支,其中的某些问题不能在概率学框架下完整解决。这类问题中不存在样本空间 Ω \Omega Ω E \mathbb{E} E observables(可观测量) 的线性算子。
Example 13. Wagers(打赌). 概率学家们曾思考一个问题,支付一定的费用开启游戏,然后根据你在游戏中的表现给予奖励,例如我将一枚硬币掩藏在掌下,然后邀请一位朋友支付 1 1 1 2 2 2
这样的游戏看起来很公平,因为庄家和玩家最终收益的期望值均为 0 0 0
但是,如果我将游戏的奖励换成 2 10 2^{10} 2 1 0 2 9 2^{9} 2 9
虽然收益的期望值还是 0 0 0
由此可见,游戏的公平性与合理性并不等价,玩家对待小赌和大赌的态度是不同的,尽管获胜的概率都是 50 % 50\% 5 0 %
我们引入 utility function(效用函数) u ( x ) u(x) u ( x ) x x x
1 2 ( u ( 0 ) + u ( 2 10 ) ) \frac{1}{2}(u(0)+u(2^{10})) 2 1 ( u ( 0 ) + u ( 2 1 0 ) )
当然,每个人的效用函数都是不同的,但是都满足 u ( 0 ) = 0 u(0)=0 u ( 0 ) = 0 u u u x x x u ( x ) u(x) u ( x ) x x x u u u
u ( x ) ≤ x u ( 1 ) for x ≥ 1 u(x)\leq xu(1) \quad \text{for } x\geq 1 u ( x ) ≤ x u ( 1 ) for x ≥ 1
效用函数是微观经济学中的常用概念,它衡量了消费者对于某次消费的满意程度,其中包含了三条重要原理:
人对于财富的占有多多益善,即 u ′ ( x ) > 0 u^{\prime}(x)>0 u ′ ( x ) > 0
随着财富的增加,满足程度的增加速度不断下降,即 u ′ ′ ( x ) < 0 u^{\prime\prime}(x)<0 u ′ ′ ( x ) < 0
在随机条件下,人的决策行为准则是获得最大期望效用值而非最大期望金额。
这也验证了经济市场中的一个准则:
no free lunch with vanishing risk \text{no free lunch with vanishing risk} no free lunch with vanishing risk
Example 14. Joy 现有 100 100 1 0 0 u ( x ) = x u(x)=\sqrt{x} u ( x ) = x Joy 有 0.1 0.1 0 . 1 100 100 1 0 0 Joy 的室友 Mary 从未睡过头,Joy 可以向她支付一定的费用请她帮忙在考试当天叫醒自己,求 Joy 愿意支付的最大费用。
如果采用决策一,即顺天应命不接受叫醒服务,则期望效用为
u 1 = 9 10 100 = 9 u_{1}=\frac{9}{10}\sqrt{100}=9 u 1 = 1 0 9 1 0 0 = 9
如果采用决策二,花费 x x x
u 2 = 100 − x u_{2}=\sqrt{100-x} u 2 = 1 0 0 − x
我们发现当 x ≤ 19 x\leq 19 x ≤ 1 9 u 2 ≤ u 1 u_{2}\leq u_{1} u 2 ≤ u 1 19 19 1 9
Example 15. St Peterburg paradox(圣彼得堡悖论) 重复投掷一枚均匀的硬币,直到出现正面朝上为止,记投掷次数为 k k k 2 k 2^{k} 2 k
我们发现一次游戏的期望收益为
∑ k = 1 ∞ 2 − k ⋅ 2 k = ∞ \sum_{k=1}^{\infty} 2^{-k} \cdot 2^{k}=\infty k = 1 ∑ ∞ 2 − k ⋅ 2 k = ∞
即如果玩家希望实现自己的收益最大化,只要能够参加游戏,付出多少钱都是可以接受的,然而事实并非如此。
我们知道随着试验次数的增加,试验的结果将会接近其数学期望,设玩家进行了 N N N
W ≈ log N log 2 W\approx \frac{\log{N}}{\log{2}} W ≈ log 2 log N
虽然随着 N N N W W W 1 1 1 N ≈ 1 0 301000000 N\approx 10^{301000000} N ≈ 1 0 3 0 1 0 0 0 0 0 0
这个例子告诉我们不能完全按照期望来做决策,我们还需要考虑期望和实验次数的关系。
Exercise 16. Coupons(礼券). 某商场发行了 c c c j j j j + 1 j+1 j + 1
难度:★★☆☆☆(点击查看答案) (1)已经拥有 j j j X X X
P ( X = 1 ) = c − j c , P ( X = 0 ) = j c \mathbb{P}(X=1)=\frac{c-j}{c},\quad \mathbb{P}(X=0)=\frac{j}{c} P ( X = 1 ) = c c − j , P ( X = 0 ) = c j
设用时为 n n n
E ( n X ) = n E ( X ) = n ( c − j ) c = 1 ⇒ n = c c − j \mathbb{E}(nX)=n\mathbb{E}(X)=\frac{n(c-j)}{c}=1\Rightarrow n=\frac{c}{c-j} E ( n X ) = n E ( X ) = c n ( c − j ) = 1 ⇒ n = c − j c
(2)有了上一问的经验就很简单了
A n s = ∑ j = 0 c − 1 c c − j = c ∑ k = 1 c 1 k Ans=\sum_{j=0}^{c-1} \frac{c}{c-j}=c \sum_{k=1}^{c} \frac{1}{k} A n s = j = 0 ∑ c − 1 c − j c = c k = 1 ∑ c k 1
Exercise 17. n n n
难度:★★★★☆(点击查看答案) (1)设 I i j I_{ij} I i j i , j i,j i , j
E ( I i j ) = P ( I i j = 1 ) = ∑ i = 1 6 ( 1 6 ) 2 = 1 6 , i ≠ j \mathbb{E}\left(I_{i j}\right)=\mathbb{P}\left(I_{i j}=1\right)=\sum_{i=1}^{6}\left(\frac{1}{6}\right)^{2}=\frac{1}{6}, \quad i \neq j E ( I i j ) = P ( I i j = 1 ) = i = 1 ∑ 6 ( 6 1 ) 2 = 6 1 , i = j
var ( I i j ) = E ( I i j 2 ) − E 2 ( I i j ) = 1 6 − 1 36 = 5 36 , i ≠ j \operatorname{var}(I_{ij})=\mathbb{E}(I^{2}_{ij})-\mathbb{E}^{2}(I_{ij})=\frac{1}{6}-\frac{1}{36}=\frac{5}{36},\quad i\neq j v a r ( I i j ) = E ( I i j 2 ) − E 2 ( I i j ) = 6 1 − 3 6 1 = 3 6 5 , i = j
设集体总分为 S S S
E ( S ) = ∑ i < j E ( I i j ) = 1 6 ( n 2 ) \mathbb{E}(S)=\sum_{i<j} \mathbb{E}\left(I_{i j}\right)=\frac{1}{6}\binom{n}{2} E ( S ) = i < j ∑ E ( I i j ) = 6 1 ( 2 n )
事实上,随机变量组 { I i j ∣ i < j } \left\{I_{i j}\mid i<j\right\} { I i j ∣ i < j }
E ( I i j I j k ) = P ( i , j , k throw same number ) = ∑ r = 1 6 ( 1 6 ) 3 = 1 36 = E ( I i j ) E ( I j k ) \begin{aligned}
\mathbb{E}\left(I_{i j} I_{j k}\right)&=\mathbb{P}(i, j, k \text { throw same number})\\
&=\sum_{r=1}^{6}\left(\frac{1}{6}\right)^{3}=\frac{1}{36}=\mathbb{E}\left(I_{i j}\right) \mathbb{E}\left(I_{j k}\right)
\end{aligned} E ( I i j I j k ) = P ( i , j , k throw same number ) = r = 1 ∑ 6 ( 6 1 ) 3 = 3 6 1 = E ( I i j ) E ( I j k )
因此,根据方差的性质
var ( S ) = var ( ∑ i < j I i j ) = ∑ i < j var ( I i j ) = 5 36 ( n 2 ) \operatorname{var}(S)=\operatorname{var}\left(\sum_{i<j} I_{i j}\right)=\sum_{i<j} \operatorname{var}\left(I_{i j}\right)=\frac{5}{36}\binom{n}{2} v a r ( S ) = v a r ( i < j ∑ I i j ) = i < j ∑ v a r ( I i j ) = 3 6 5 ( 2 n )
(2)设 X i j X_{ij} X i j i , j i,j i , j
E ( X i j ) = ∑ i = 1 6 i ( 1 6 ) 2 = 7 12 , i ≠ j \mathbb{E}\left(X_{i j}\right)=\sum_{i=1}^{6}i\left(\frac{1}{6}\right)^{2}=\frac{7}{12}, \quad i \neq j E ( X i j ) = i = 1 ∑ 6 i ( 6 1 ) 2 = 1 2 7 , i = j
E ( S ) = ∑ i < j E ( X i j ) = 7 12 ( n 2 ) \mathbb{E}(S)=\sum_{i<j} \mathbb{E}\left(X_{i j}\right)=\frac{7}{12}\binom{n}{2} E ( S ) = i < j ∑ E ( X i j ) = 1 2 7 ( 2 n )
现在 X i j X_{ij} X i j
var ( S ) = E { ( ∑ i < j X i j ) 2 } − E 2 ( S ) = ( n 2 ) E ( X 12 2 ) + ( n 3 ) E ( X 12 X 23 ) + { ( n 2 ) 2 − ( n 2 ) − ( n 3 ) } E ( X 12 ) 2 − ( 7 12 ) 2 ( n 2 ) 2 = 315 144 ( n 2 ) + 35 432 ( n 3 ) \begin{aligned}
\operatorname{var}(S) &=\mathbb{E}\left\{\left(\sum_{i<j} X_{i j}\right)^{2}\right\}-\mathbb{E}^{2}(S) \\
&=\binom{n}{2} \mathbb{E}\left(X_{12}^{2}\right)+\binom{n}{3} \mathbb{E}\left(X_{12} X_{23}\right)+\left\{\binom{n}{2}^{2}-\binom{n}{2}-\binom{n}{3}\right\} \mathbb{E}\left(X_{12}\right)^{2}-\left(\frac{7}{12}\right)^{2}\binom{n}{2}^{2} \\
&=\frac{315}{144}\binom{n}{2}+\frac{35}{432}\binom{n}{3}
\end{aligned} v a r ( S ) = E ⎩ ⎪ ⎨ ⎪ ⎧ ( i < j ∑ X i j ) 2 ⎭ ⎪ ⎬ ⎪ ⎫ − E 2 ( S ) = ( 2 n ) E ( X 1 2 2 ) + ( 3 n ) E ( X 1 2 X 2 3 ) + { ( 2 n ) 2 − ( 2 n ) − ( 3 n ) } E ( X 1 2 ) 2 − ( 1 2 7 ) 2 ( 2 n ) 2 = 1 4 4 3 1 5 ( 2 n ) + 4 3 2 3 5 ( 3 n )
注:以上是官方所给答案,但是博主认为上述过程中没有考虑到 X i j , X i k X_{ij},X_{ik} X i j , X i k
var ( S ) = ( n 2 ) E ( X 12 2 ) + 6 ( n 3 ) E ( X 12 X 23 ) + 6 ( n 4 ) E 2 ( X 12 ) − ( 7 12 ) 2 ( n 2 ) 2 = 91 36 ( n 2 ) + 91 36 ( n 3 ) + 24 49 ( n 4 ) − 49 144 ( n 2 ) 2 \begin{aligned}\operatorname{var}(S)
&=\binom{n}{2}\mathbb{E}(X^{2}_{12})+6\binom{n}{3}\mathbb{E}(X_{12}X_{23})+6\binom{n}{4}\mathbb{E}^{2}(X_{12})-\left(\frac{7}{12}\right)^{2}\binom{n}{2}^{2}\\
&=\frac{91}{36}\binom{n}{2}+\frac{91}{36}\binom{n}{3}+\frac{24}{49}\binom{n}{4}-\frac{49}{144}\binom{n}{2}^{2}
\end{aligned} v a r ( S ) = ( 2 n ) E ( X 1 2 2 ) + 6 ( 3 n ) E ( X 1 2 X 2 3 ) + 6 ( 4 n ) E 2 ( X 1 2 ) − ( 1 2 7 ) 2 ( 2 n ) 2 = 3 6 9 1 ( 2 n ) + 3 6 9 1 ( 3 n ) + 4 9 2 4 ( 4 n ) − 1 4 4 4 9 ( 2 n ) 2
注意到 ( n 2 ) + 6 ( n 3 ) + 6 ( n 4 ) = ( n 2 ) 2 \binom{n}{2}+6\binom{n}{3}+6\binom{n}{4}=\binom{n}{2}^{2} ( 2 n ) + 6 ( 3 n ) + 6 ( 4 n ) = ( 2 n ) 2
var ( S ) = 315 144 ( n 2 ) + 35 72 ( n 3 ) \operatorname{var}(S)=\frac{315}{144}\binom{n}{2}+\frac{35}{72}\binom{n}{3} v a r ( S ) = 1 4 4 3 1 5 ( 2 n ) + 7 2 3 5 ( 3 n )
Exercise 18. Arbitrage(套利). 在一场赌马游戏中,共 n n n k k k π ( k ) \pi(k) π ( k ) ∑ k = 1 n 1 π ( k ) + 1 < 1 \sum_{k=1}^{n}\frac{1}{\pi(k)+1}<1 k = 1 ∑ n π ( k ) + 1 1 < 1
难度:★★☆☆☆(点击查看答案) 我们在所有的赛马上下注,第 k k k 1 π ( k ) + 1 \frac{1}{\pi(k)+1} π ( k ) + 1 1 1 1 1 1 1 1
4、Indicators and matching(指示函数和匹配问题) 本节我们介绍一些指示函数的应用,在 Example 2.1.8 中我们定义了指示函数
I A ( ω ) = { 1 if ω ∈ A 0 if ω ∈ A c I_{A}(\omega)=\left\{\begin{array}{ll}
1 & \text { if } \omega \in A \\
0 & \text { if } \omega \in A^{c}
\end{array}\right. I A ( ω ) = { 1 0 if ω ∈ A if ω ∈ A c
并且我们知道 E I A = P ( A ) \mathbb{E} I_{A}=\mathbb{P}(A) E I A = P ( A )
Example 1. 我们尝试用指示函数证明 Lemma 1.3.6 ,即P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A ∩ B ) \mathbb{P}(A \cup B)=\mathbb{P}(A)+\mathbb{P}(B)-\mathbb{P}(A \cap B) P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A ∩ B )
显然,对于指示函数,有
I A ∪ A c = 1 , I A ∩ B = I A I B I_{A \cup A^{c}}=1,\quad I_{A \cap B}=I_{A} I_{B} I A ∪ A c = 1 , I A ∩ B = I A I B
因此
I A ∪ B = 1 − I ( A ∪ B ) c = 1 − I A c ∩ B c = 1 − I A c I B c = 1 − ( 1 − I A ) ( 1 − I B ) = I A + I B − I A I B \begin{aligned}
I_{A \cup B} &=1-I_{(A \cup B)^{c}}=1-I_{A^{c} \cap B^{c}} \\
&=1-I_{A^{c}} I_{B^{c}}=1-\left(1-I_{A}\right)\left(1-I_{B}\right) \\
&=I_{A}+I_{B}-I_{A} I_{B}
\end{aligned} I A ∪ B = 1 − I ( A ∪ B ) c = 1 − I A c ∩ B c = 1 − I A c I B c = 1 − ( 1 − I A ) ( 1 − I B ) = I A + I B − I A I B
两边取期望得到
P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A ∩ B ) \mathbb{P}(A \cup B)=\mathbb{P}(A)+\mathbb{P}(B)-\mathbb{P}(A \cap B) P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A ∩ B )
更一般的,设 B = ⋃ i = 1 n A i B=\bigcup_{i=1}^{n} A_{i} B = ⋃ i = 1 n A i
I B = 1 − ∏ i = 1 n ( 1 − I A i ) I_{B}=1-\prod_{i=1}^{n}\left(1-I_{A_{i}}\right) I B = 1 − i = 1 ∏ n ( 1 − I A i )
把乘积展开后两边取期望得到
P ( ⋃ i = 1 n A i ) = ∑ i P ( A i ) − ∑ i < j P ( A i ∩ A j ) + ⋯ + ( − 1 ) n + 1 P ( A 1 ∩ ⋯ ∩ A n ) \mathbb{P}\left(\bigcup_{i=1}^{n} A_{i}\right)=\sum_{i} \mathbb{P}\left(A_{i}\right)-\sum_{i<j} \mathbb{P}\left(A_{i} \cap A_{j}\right)+\cdots+(-1)^{n+1} \mathbb{P}\left(A_{1} \cap \cdots \cap A_{n}\right) P ( i = 1 ⋃ n A i ) = i ∑ P ( A i ) − i < j ∑ P ( A i ∩ A j ) + ⋯ + ( − 1 ) n + 1 P ( A 1 ∩ ⋯ ∩ A n )
这个恒等式称为 inclusion-exclusion formula(容斥公式) .
Example 2. Matching problem(匹配问题). 一位秘书打印了 n n n r r r
设 L 1 , L 2 , … , L n L_{1},L_{2},\ldots,L_{n} L 1 , L 2 , … , L n A i A_{i} A i L i L_{i} L i I i I_{i} I i A i A_{i} A i
S = ∑ π I j 1 ⋯ I j r ( 1 − I k r + 1 ) ⋯ ( 1 − I k n ) S=\sum_{\pi} I_{j_{1}} \cdots I_{j_{r}}\left(1-I_{k_{r+1}}\right) \cdots\left(1-I_{k_{n}}\right) S = π ∑ I j 1 ⋯ I j r ( 1 − I k r + 1 ) ⋯ ( 1 − I k n )
其中 j 1 , … , j r , k r + 1 , … , k n j_{1},\ldots,j_{r},k_{r+1},\ldots,k_{n} j 1 , … , j r , k r + 1 , … , k n 1 , 2 , … , n 1,2,\ldots,n 1 , 2 , … , n X X X
S = { 0 if X ≠ r r ! ( n − r ) ! if X = r S=\left\{\begin{array}{ll}
0 & \text { if } X \neq r \\
r !(n-r) ! & \text { if } X=r
\end{array}\right. S = { 0 r ! ( n − r ) ! if X = r if X = r
我们要求的事件是 { X = r } \{X=r\} { X = r }
I = 1 r ! ( n − r ) ! S I=\frac{1}{r !(n-r) !} S I = r ! ( n − r ) ! 1 S
也就是说,我们只要求出 E ( S ) \mathbb{E}(S) E ( S ) S S S
E ( S ) = ∑ π ∑ s = 0 n − r ( − 1 ) s ( n − r s ) E ( I j 1 ⋯ I j r I k r + 1 ⋯ I k r + s ) \mathbb{E}(S)=\sum_{\pi} \sum_{s=0}^{n-r}(-1)^{s}\binom{n-r}{s} \mathbb{E}\left(I_{j_{1}} \cdots I_{j_{r}} I_{k_{r+1}} \cdots I_{k_{r+s}}\right) E ( S ) = π ∑ s = 0 ∑ n − r ( − 1 ) s ( s n − r ) E ( I j 1 ⋯ I j r I k r + 1 ⋯ I k r + s )
而 E ( I j 1 ⋯ I j r I k r + 1 ⋯ I k r + s ) \mathbb{E}\left(I_{j_{1}} \cdots I_{j_{r}} I_{k_{r+1}} \cdots I_{k_{r+s}}\right) E ( I j 1 ⋯ I j r I k r + 1 ⋯ I k r + s ) L j 1 , … , L j r , L k r + 1 , L k r + s L_{j_{1}},\ldots,L_{j_{r}},L_{k_{r+1}},L_{k_{r+s}} L j 1 , … , L j r , L k r + 1 , L k r + s
E ( I j 1 ⋯ I j r I k r + 1 ⋯ I k r + s ) = ( n − r − s ) ! n ! \mathbb{E}\left(I_{j_{1}} \cdots I_{j_{r}} I_{k_{r+1}} \cdots I_{k_{r+s}}\right)=\frac{(n-r-s) !}{n !} E ( I j 1 ⋯ I j r I k r + 1 ⋯ I k r + s ) = n ! ( n − r − s ) !
将这些公式代入得到
P ( X = r ) = E ( I ) = 1 r ! ( n − r ) ! E ( S ) = 1 r ! ( n − r ) ! ∑ s = 0 n − r ( − 1 ) s ( n − r s ) n ! ( n − r − s ) ! n ! = 1 r ! ∑ s = 0 n − r ( − 1 ) s 1 s ! \begin{aligned}
\mathbb{P}(X=r) &=\mathbb{E}(I)=\frac{1}{r !(n-r) !} \mathbb{E}(S) \\
&=\frac{1}{r !(n-r) !} \sum_{s=0}^{n-r}(-1)^{s}\binom{n-r}{s} n ! \frac{(n-r-s) !}{n !} \\
&=\frac{1}{r !} \sum_{s=0}^{n-r}(-1)^{s} \frac{1}{s !}
\end{aligned} P ( X = r ) = E ( I ) = r ! ( n − r ) ! 1 E ( S ) = r ! ( n − r ) ! 1 s = 0 ∑ n − r ( − 1 ) s ( s n − r ) n ! n ! ( n − r − s ) ! = r ! 1 s = 0 ∑ n − r ( − 1 ) s s ! 1
特别的,当 n → ∞ n\rightarrow \infty n → ∞
lim n → ∞ ∑ s = 0 n ( − 1 ) s s ! = e − 1 \lim_{n\rightarrow \infty} \sum_{s=0}^{n}\frac{(-1)^s}{s!}=e^{-1} n → ∞ lim s = 0 ∑ n s ! ( − 1 ) s = e − 1
事实上,我们可以使用容斥公式更简单的解决匹配问题,留作练习。
Example 3. The probabilistic method(概率学方法). 一块土地的外围有 17 17 1 7 5 5 5 7 7 7 3 3 3
我们给护栏编号为 1 , 2 , … , 17 1,2,\ldots,17 1 , 2 , … , 1 7 I k I_{k} I k k k k R k R_{k} R k k + 1 , k + 2 , … , k + 7 ( m o d 17 ) k+1,k+2,\ldots,k+7\pmod{17} k + 1 , k + 2 , … , k + 7 ( m o d 1 7 )
现在,我们等概率的随机选取一根护栏 K K K
E ( R K ) = 1 17 ∑ k = 1 17 ( I k + 1 + I k + 2 + ⋯ + I k + 7 ) = ∑ j = 1 17 7 17 I j = 7 17 ⋅ 5 > 2 \mathbb{E}\left(R_{K}\right)=\frac{1}{17}\sum_{k=1}^{17} \left(I_{k+1}+I_{k+2}+\cdots+I_{k+7}\right)=\sum_{j=1}^{17} \frac{7}{17} I_{j}=\frac{7}{17} \cdot 5>2 E ( R K ) = 1 7 1 k = 1 ∑ 1 7 ( I k + 1 + I k + 2 + ⋯ + I k + 7 ) = j = 1 ∑ 1 7 1 7 7 I j = 1 7 7 ⋅ 5 > 2
由于 R k R_{k} R k P ( R K ≥ 3 ) > 0 \mathbb{P}\left(R_{K} \geq 3\right)>0 P ( R K ≥ 3 ) > 0
Exercise 4. The probabilistic method(概率学方法). 设 G = ( V , E ) G=(V,E) G = ( V , E ) W W W e ∈ E e\in E e ∈ E I W ( e ) = { 1 if e connects W and W c 0 otherwise I_{W}(e)=\left\{\begin{array}{ll}1 & \text { if } e \text { connects } W \text { and } W^{\mathrm{c}} \\ 0 & \text { otherwise }\end{array}\right. I W ( e ) = { 1 0 if e connects W and W c otherwise N W = ∑ e ∈ E I W ( e ) N_{W}=\sum_{e \in E} I_{W}(e) N W = ∑ e ∈ E I W ( e ) W ⊆ W\subseteq W ⊆ N W ≥ 1 2 ∣ E ∣ N_{W} \geq \frac{1}{2}|E| N W ≥ 2 1 ∣ E ∣
难度:★★★☆☆(点击查看答案) 我们对图 G G G 1 2 \frac{1}{2} 2 1 W W W N W N_{W} N W
E N W = 1 2 ∣ E ∣ , P ( N W > 1 2 ∣ E ∣ ) > 0 \mathbb{E} N_{W}=\frac{1}{2}|E|, \quad \mathbb{P}(N_{W}>\frac{1}{2}|E|)>0 E N W = 2 1 ∣ E ∣ , P ( N W > 2 1 ∣ E ∣ ) > 0
Example 1. Bernoulli trials(伯努利试验). 随机变量 X X X 0 , 1 0,1 0 , 1 p , q = 1 − p p,q=1-p p , q = 1 − p X X X 0 , 1 0,1 0 , 1 f ( 0 ) = 1 − p , f ( 1 ) = p f(0)=1-p, \quad f(1)=p f ( 0 ) = 1 − p , f ( 1 ) = p E X = p \mathbb{E} X=p E X = p var ( X ) = p ( 1 − p ) \operatorname{var}(X)=p(1-p) v a r ( X ) = p ( 1 − p )
Example 2. Binomial distribution(二项分布). 我们进行 n n n X 1 , X 2 , … , X n X_{1}, X_{2}, \ldots, X_{n} X 1 , X 2 , … , X n Y = X 1 + X 2 + ⋯ + X n Y=X_{1}+X_{2}+\cdots+X_{n} Y = X 1 + X 2 + ⋯ + X n Example 3.1.3 的讨论,Y Y Y f ( k ) = ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , … , n f(k)=\binom{n}{k} p^{k}(1-p)^{n-k}, \quad k=0,1, \ldots, n f ( k ) = ( k n ) p k ( 1 − p ) n − k , k = 0 , 1 , … , n Theorem 3.3.9 和 Theorem 3.3.11 可得E Y = n p , var ( Y ) = n p ( 1 − p ) \mathbb{E} Y=n p, \quad \operatorname{var}(Y)=n p(1-p) E Y = n p , v a r ( Y ) = n p ( 1 − p )
Example 3. Trinomial distribution(三项分布). 我们进行 n n n 3 3 3 p , q , 1 − p − q p,q,1-p-q p , q , 1 − p − q r , w , n − r − w r,w,n-r-w r , w , n − r − w n ! r ! w ! ( n − r − w ) ! p r q w ( 1 − p − q ) n − r − w \frac{n !}{r ! w !(n-r-w) !} p^{r} q^{w}(1-p-q)^{n-r-w} r ! w ! ( n − r − w ) ! n ! p r q w ( 1 − p − q ) n − r − w n , p , q n,p,q n , p , q t t t multinomial distribution(多项分布) .
Example 4. Poisson distribution(泊松分布). 泊松随机变量是指服从质量函数f ( k ) = λ k k ! e − λ , k = 0 , 1 , 2 , … f(k)=\frac{\lambda^{k}}{k !} e^{-\lambda}, \quad k=0,1,2, \ldots f ( k ) = k ! λ k e − λ , k = 0 , 1 , 2 , … λ > 0 \lambda>0 λ > 0 λ \lambda λ
泊松分布的由来如下,设随机变量 Y ∼ bin ( n , p ) Y\sim \text{bin}(n,p) Y ∼ bin ( n , p ) λ = E ( Y ) = n p \lambda=\mathbb{E}(Y)=n p λ = E ( Y ) = n p n → ∞ , p → 0 n \rightarrow \infty, p \rightarrow 0 n → ∞ , p → 0
P ( Y = k ) = ( n k ) p k ( 1 − p ) n − k ∼ 1 k ! ( n p 1 − p ) k ( 1 − p ) n → λ k k ! e − λ \mathbb{P}(Y=k)=\binom{n}{k} p^{k}(1-p)^{n-k} \sim \frac{1}{k !}\left(\frac{n p}{1-p}\right)^{k}(1-p)^{n} \rightarrow \frac{\lambda^{k}}{k !} e^{-\lambda} P ( Y = k ) = ( k n ) p k ( 1 − p ) n − k ∼ k ! 1 ( 1 − p n p ) k ( 1 − p ) n → k ! λ k e − λ
Example 5. Geometric distribution(几何分布). 几何随机变量是指服从质量函数f ( k ) = p ( 1 − p ) k − 1 , k = 1 , 2 , … f(k)=p(1-p)^{k-1}, \quad k=1,2, \ldots f ( k ) = p ( 1 − p ) k − 1 , k = 1 , 2 , … p ∈ ( 0 , 1 ) p\in (0,1) p ∈ ( 0 , 1 ) p − 1 p^{-1} p − 1 ( 1 − p ) p − 2 (1-p)p^{-2} ( 1 − p ) p − 2
几何分布的由来如下,不断进行参数为 p p p W W W W W W waiting time(等待时长) ,那么显然 P ( W > k ) = ( 1 − p ) k \mathbb{P}(W>k)=(1-p)^{k} P ( W > k ) = ( 1 − p ) k
P ( W = k ) = P ( W > k − 1 ) − P ( W > k ) = p ( 1 − p ) k − 1 \mathbb{P}(W=k)=\mathbb{P}(W>k-1)-\mathbb{P}(W>k)=p(1-p)^{k-1} P ( W = k ) = P ( W > k − 1 ) − P ( W > k ) = p ( 1 − p ) k − 1
Example 6. Negative binomal distribution(负二项分布). 负二项分布是几何分布的扩展,设 W r W_{r} W r r r r W r W_{r} W r P ( W r = k ) = ( k − 1 r − 1 ) p r ( 1 − p ) k − r , k = r , r + 1 , … \mathbb{P}\left(W_{r}=k\right)=\binom{k-1}{r-1} p^{r}(1-p)^{k-r}, \quad k=r, r+1, \ldots P ( W r = k ) = ( r − 1 k − 1 ) p r ( 1 − p ) k − r , k = r , r + 1 , … W r W_{r} W r r r r X i X_{i} X i i − 1 i-1 i − 1 i i i X 1 , X 2 , … , X r X_{1},X_{2},\ldots,X_{r} X 1 , X 2 , … , X r W r = X 1 + X 2 + ⋯ + X r W_{r}=X_{1}+X_{2}+\cdots+X_{r} W r = X 1 + X 2 + ⋯ + X r Theorem 3.3.8 和 Theorem 3.3.11 不难求出 W r W_{r} W r
Exercise 7. 设 X X X P ( X = n ) = p n ( λ ) = λ n n ! e − λ , for n ≥ 0 \mathbb{P}(X=n)=p_{n}(\lambda)=\frac{\lambda^{n}}{n!}e^{-\lambda}, \quad\text { for } n \geq 0 P ( X = n ) = p n ( λ ) = n ! λ n e − λ , for n ≥ 0 P ( X ≤ n ) = 1 − ∫ 0 λ p n ( x ) d x \mathbb{P}(X \leq n)=1-\int_{0}^{\lambda} p_{n}(x) d x P ( X ≤ n ) = 1 − ∫ 0 λ p n ( x ) d x
难度:★★★☆☆(点击查看答案) 我们将要证的式子两边对 λ \lambda λ
d d λ { P ( X ≤ n ) } = − p n ( λ ) \frac{d}{d\lambda}\{\mathbb{P}(X\leq n)\}=-p_n(\lambda) d λ d { P ( X ≤ n ) } = − p n ( λ )
而 P ( X ≤ n ) = ∑ i = 0 n p i ( λ ) \mathbb{P}(X\leq n)=\sum_{i=0}^{n}p_{i}(\lambda) P ( X ≤ n ) = ∑ i = 0 n p i ( λ )
d d λ { P ( X ≤ n ) } = ∑ i = 0 n d d λ p i ( λ ) = ∑ i = 0 n i λ i − 1 e − λ − λ i e − λ i ! = ∑ i = 0 n { p i − 1 ( λ ) − p i ( λ ) } = − p n ( λ ) \begin{aligned}
\frac{d}{d\lambda}\{\mathbb{P}(X\leq n)\}&=\sum_{i=0}^{n}\frac{d}{d\lambda}p_{i}(\lambda)=\sum_{i=0}^{n}\frac{i\lambda^{i-1}e^{-\lambda}-\lambda^{i}e^{-\lambda}}{i!}\\
&=\sum_{i=0}^{n}\{p_{i-1}(\lambda)-p_{i}(\lambda)\}=-p_{n}(\lambda)
\end{aligned} d λ d { P ( X ≤ n ) } = i = 0 ∑ n d λ d p i ( λ ) = i = 0 ∑ n i ! i λ i − 1 e − λ − λ i e − λ = i = 0 ∑ n { p i − 1 ( λ ) − p i ( λ ) } = − p n ( λ )
两边对 λ \lambda λ
P ( X ≤ n ) = C − ∫ 0 λ p n ( x ) d x \mathbb{P}(X \leq n)=C-\int_{0}^{\lambda} p_{n}(x) d x P ( X ≤ n ) = C − ∫ 0 λ p n ( x ) d x
令 n = 0 n=0 n = 0 C = 1 C=1 C = 1
Exercise 8. Capture-recapture(重复捕捉) 某动物群体中共有 b b b a a a X X X m m m P ( X = n ) = a b ( a − 1 m − 1 ) ( b − a n − m ) / ( b − 1 n − 1 ) \left.{\mathbb{P}(X=n)=\frac{a}{b}\binom{a-1}{m-1}\binom{b-a}{n-m}}\middle/ \binom{b-1}{n-1}\right. P ( X = n ) = b a ( m − 1 a − 1 ) ( n − m b − a ) / ( n − 1 b − 1 ) E X \mathbb{E} X E X X X X negative hypergeometric distribution(负超几何分布) .
难度:★★★☆☆(点击查看答案) 为了满足条件,第 n n n n − 1 n-1 n − 1 m − 1 m-1 m − 1 a b ( a − 1 m − 1 ) ( b − a n − m ) \frac{a}{b}\binom{a-1}{m-1}\binom{b-a}{n-m} b a ( m − 1 a − 1 ) ( n − m b − a ) ( b − 1 n − 1 ) \binom{b-1}{n-1} ( n − 1 b − 1 )
设 X j X_{j} X j j − 1 j-1 j − 1 j j j
∑ j = 0 a E X j = b − a \sum_{j=0}^{a}\mathbb{E}X_{j}=b-a j = 0 ∑ a E X j = b − a
根据对称性,有 E X 1 = E X 2 = ⋯ = E X n = b − a a + 1 \mathbb{E}X_{1}=\mathbb{E}X_{2}=\cdots=\mathbb{E}X_{n}=\frac{b-a}{a+1} E X 1 = E X 2 = ⋯ = E X n = a + 1 b − a
E X = ∑ j = 1 m ( E X j + 1 ) = m ( b + 1 ) a + 1 \mathbb{E}X=\sum_{j=1}^{m}(\mathbb{E}X_{j}+1)=\frac{m(b+1)}{a+1} E X = j = 1 ∑ m ( E X j + 1 ) = a + 1 m ( b + 1 )
概率论常常考虑一组随机变量,这些随机变量之间往往不完全是独立的。
我们需要一个工具来研究这些相互关联的随机变量组,下面我们以两个随机变量为例,来研究它们的相关性。
Definition 1. 离散型随机变量 X , Y X,Y X , Y joint distribution function(联合分布函数) F : R 2 → [ 0 , 1 ] F: \mathbb{R}^{2} \rightarrow[0,1] F : R 2 → [ 0 , 1 ] F ( x , y ) = P ( X ≤ x and Y ≤ y ) F(x, y)=\mathbb{P}(X \leq x \text { and } Y \leq y) F ( x , y ) = P ( X ≤ x and Y ≤ y ) joint mass function(联合质量函数) f : R 2 → [ 0 , 1 ] f: \mathbb{R}^{2} \rightarrow[0,1] f : R 2 → [ 0 , 1 ] f ( x , y ) = P ( X = x and Y = y ) f(x, y)=\mathbb{P}(X=x \text { and } Y=y) f ( x , y ) = P ( X = x and Y = y )
多个随机变量的联合分布函数与联合质量函数的定义也是一样的。
当需要指明随机变量的符号时,我们用 F X , Y F_{X,Y} F X , Y f X , Y f_{X,Y} f X , Y X , Y X,Y X , Y
Lemma 2. 离散型随机变量 X , Y X,Y X , Y f X , Y ( x , y ) = f X ( x ) f Y ( y ) for all x , y ∈ R f_{X, Y}(x, y)=f_{X}(x) f_{Y}(y) \quad \text { for all } x, y \in \mathbb{R} f X , Y ( x , y ) = f X ( x ) f Y ( y ) for all x , y ∈ R X , Y X,Y X , Y f X , Y ( x , y ) f_{X,Y}(x,y) f X , Y ( x , y ) x x x g ( x ) g(x) g ( x ) y y y h ( y ) h(y) h ( y ) f X , Y ( x , y ) = g ( x ) h ( y ) f_{X,Y}(x,y)=g(x)h(y) f X , Y ( x , y ) = g ( x ) h ( y )
证明:(1)设事件 A x = { X = x } , B y = { Y = y } A_{x}=\{X=x\},B_{y}=\{Y=y\} A x = { X = x } , B y = { Y = y }
f X , Y ( x , y ) = P ( A x ∩ B y ) f_{X,Y}(x, y)=\mathbb{P}\left(A_{x} \cap B_{y}\right) f X , Y ( x , y ) = P ( A x ∩ B y )
根据 Definition 3.2.1 ,若 X , Y X,Y X , Y
f X , Y ( x , y ) = P ( A x ) P ( B y ) = f X ( x ) f Y ( y ) f_{X,Y}(x,y)=\mathbb{P}(A_{x})\mathbb{P}(B_{y})=f_{X}(x)f_{Y}(y) f X , Y ( x , y ) = P ( A x ) P ( B y ) = f X ( x ) f Y ( y )
若 f X , Y ( x , y ) = f X ( x ) f Y ( y ) f_{X, Y}(x, y)=f_{X}(x) f_{Y}(y) f X , Y ( x , y ) = f X ( x ) f Y ( y ) x , y ∈ R x,y\in \mathbb{R} x , y ∈ R
P ( A x ∩ B y ) = P ( A x ) P ( B y ) ⇒ X , Y 独立 \mathbb{P}\left(A_{x} \cap B_{y}\right)=\mathbb{P}(A_{x})\mathbb{P}(B_{y})\Rightarrow X,Y 独立 P ( A x ∩ B y ) = P ( A x ) P ( B y ) ⇒ X , Y 独 立
(2)若 f X , Y ( x , y ) = g ( x ) h ( y ) f_{X,Y}(x,y)=g(x)h(y) f X , Y ( x , y ) = g ( x ) h ( y )
f X ( x ) = ∑ y f X , Y ( x , y ) = g ( x ) ∑ y h ( y ) f_{X}(x)=\sum_{y} f_{X, Y}(x, y)=g(x) \sum_{y} h(y) f X ( x ) = y ∑ f X , Y ( x , y ) = g ( x ) y ∑ h ( y )
f Y ( y ) = ∑ x f X , Y ( x , y ) = h ( y ) ∑ x g ( x ) f_{Y}(y)=\sum_{x} f_{X, Y}(x, y)=h(y) \sum_{x} g(x) f Y ( y ) = x ∑ f X , Y ( x , y ) = h ( y ) x ∑ g ( x )
而 ∑ x g ( x ) ∑ y h ( y ) = 1 \sum_{x} g(x) \sum_{y} h(y)=1 ∑ x g ( x ) ∑ y h ( y ) = 1
f X ( x ) f Y ( y ) = g ( x ) h ( y ) ∑ x g ( x ) ∑ y h ( y ) = g ( x ) h ( y ) = f X , Y ( x , y ) f_{X}(x) f_{Y}(y)=g(x) h(y) \sum_{x} g(x) \sum_{y} h(y)=g(x) h(y)=f_{X, Y}(x, y) f X ( x ) f Y ( y ) = g ( x ) h ( y ) x ∑ g ( x ) y ∑ h ( y ) = g ( x ) h ( y ) = f X , Y ( x , y )
注:上述过程中,为了验证 f X , Y ( x , y ) = f X ( x ) f Y ( y ) f_{X, Y}(x, y)=f_{X}(x) f_{Y}(y) f X , Y ( x , y ) = f X ( x ) f Y ( y ) marginal mass function(边际质量函数) f X , f Y f_{X},f_{Y} f X , f Y
f X ( x ) = P ( X = x ) = P ( ⋃ y ( { X = x } ∩ { Y = y } ) ) = ∑ y P ( X = x , Y = y ) = ∑ y f X , Y ( x , y ) \begin{aligned}
f_{X}(x) &=\mathbb{P}(X=x)=\mathbb{P}\left(\bigcup_{y}(\{X=x\} \cap\{Y=y\})\right) \\
&=\sum_{y} \mathbb{P}(X=x, Y=y)=\sum_{y} f_{X, Y}(x, y)
\end{aligned} f X ( x ) = P ( X = x ) = P ( y ⋃ ( { X = x } ∩ { Y = y } ) ) = y ∑ P ( X = x , Y = y ) = y ∑ f X , Y ( x , y )
Example 3. Calculation of marginals(边际的计算) 在 Example 3.2.2 中,我们遇到了一对随机变量 X , Y X,Y X , Y f ( x , y ) = α x β y x ! y ! e − α − β for x , y = 0 , 1 , 2 , … f(x, y)=\frac{\alpha^{x} \beta^{y}}{x ! y !} e^{-\alpha-\beta} \quad \text { for } \quad x, y=0,1,2, \ldots f ( x , y ) = x ! y ! α x β y e − α − β for x , y = 0 , 1 , 2 , … α , β > 0 \alpha, \beta>0 α , β > 0 X X X f X ( x ) = ∑ y f ( x , y ) = α x x ! e − α ∑ y = 0 ∞ β y y ! e − β = α x x ! e − α f_{X}(x)=\sum_{y} f(x, y)=\frac{\alpha^{x}}{x !} e^{-\alpha} \sum_{y=0}^{\infty} \frac{\beta^{y}}{y !} e^{-\beta}=\frac{\alpha^{x}}{x !} e^{-\alpha} f X ( x ) = y ∑ f ( x , y ) = x ! α x e − α y = 0 ∑ ∞ y ! β y e − β = x ! α x e − α X X X α \alpha α X , Y X,Y X , Y
对于一对随机变量 X , Y X,Y X , Y g ( X , Y ) g(X,Y) g ( X , Y )
Lemma 4. 对于随机变量 X , Y X,Y X , Y g ( X , Y ) g(X,Y) g ( X , Y ) E ( g ( X , Y ) ) = ∑ x , y g ( x , y ) f X , Y ( x , y ) \mathbb{E}(g(X, Y))=\sum_{x, y} g(x, y) f_{X, Y}(x, y) E ( g ( X , Y ) ) = x , y ∑ g ( x , y ) f X , Y ( x , y )
证明:该引理的证明与 Lemma 3.3.3 类似
E ( g ( X , Y ) ) = ∑ w w P ( g ( X , Y ) = w ) = ∑ w w ∑ x , y : g ( x , y ) = w P ( X = x , Y = y ) = ∑ x , y P ( X = x , Y = y ) ∑ w : g ( x , y ) = w w = ∑ x , y F X , Y ( x , y ) g ( x , y ) \begin{aligned}
\mathbb{E}(g(X,Y))&=\sum_{w}w\mathbb{P}(g(X,Y)=w)\\
&=\sum_{w}w\sum_{x,y:g(x,y)=w}\mathbb{P}(X=x,Y=y)\\
&=\sum_{x,y}\mathbb{P}(X=x,Y=y)\sum_{w:g(x,y)=w}w\\
&=\sum_{x,y}F_{X,Y}(x,y)g(x,y)
\end{aligned} E ( g ( X , Y ) ) = w ∑ w P ( g ( X , Y ) = w ) = w ∑ w x , y : g ( x , y ) = w ∑ P ( X = x , Y = y ) = x , y ∑ P ( X = x , Y = y ) w : g ( x , y ) = w ∑ w = x , y ∑ F X , Y ( x , y ) g ( x , y )
这个公式对那些试图向门外汉解释独立性的统计学家非常重要。
假设政府希望宣布国防支出与生活费用间的相关性极小,那么不应该发表其联合质量函数的估计结果,大部分群众更喜欢用一个单独的数字来描述这种相关性的规模大小,因此我们引入下面的定义。
Definition 5. 随机变量 X , Y X,Y X , Y covariance(协方差) 定义为cov ( X , Y ) = E [ ( X − E X ) ( Y − E Y ) ] \operatorname{cov}(X, Y)=\mathbb{E}[(X-\mathbb{E} X)(Y-\mathbb{E} Y)] c o v ( X , Y ) = E [ ( X − E X ) ( Y − E Y ) ] correlation coefficient(相关系数) 定义为ρ ( X , Y ) = cov ( X , Y ) var ( X ) ⋅ var ( Y ) \rho(X, Y)=\frac{\operatorname{cov}(X, Y)}{\sqrt{\operatorname{var}(X) \cdot \operatorname{var}(Y)}} ρ ( X , Y ) = v a r ( X ) ⋅ v a r ( Y ) c o v ( X , Y )
根据协方差的定义,我们知道 cov ( X , X ) = var ( X ) \operatorname{cov}(X, X)=\operatorname{var}(X) c o v ( X , X ) = v a r ( X )
cov ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) \operatorname{cov}(X, Y)=\mathbb{E}(X Y)-\mathbb{E}(X) \mathbb{E}(Y) c o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y )
根据 Theorem 3.3.9 ,如果 cov ( X , Y ) = 0 \operatorname{cov}(X, Y)=0 c o v ( X , Y ) = 0 X , Y X,Y X , Y
Theorem 6. Cauchy-Schwarz inequality(柯西-施瓦茨不等式) 对于随机变量 X , Y X,Y X , Y E 2 ( X Y ) ≤ E ( X 2 ) E ( Y 2 ) \mathbb{E}^{2}(X Y) \leq \mathbb{E}\left(X^{2}\right) \mathbb{E}\left(Y^{2}\right) E 2 ( X Y ) ≤ E ( X 2 ) E ( Y 2 ) P ( a X = b Y ) = 1 \mathbb{P}(a X=b Y)=1 P ( a X = b Y ) = 1 a , b a,b a , b 0 0 0
证明:我们可以设 E ( X 2 ) , E ( Y 2 ) \mathbb{E}\left(X^{2}\right),\mathbb{E}\left(Y^{2}\right) E ( X 2 ) , E ( Y 2 ) Z = a X − b Y Z=a X-b Y Z = a X − b Y
0 ≤ E ( Z 2 ) = a 2 E ( X 2 ) − 2 a b E ( X Y ) + b 2 E ( Y 2 ) 0 \leq \mathbb{E}\left(Z^{2}\right)=a^{2} \mathbb{E}\left(X^{2}\right)-2 a b \mathbb{E}(X Y)+b^{2} \mathbb{E}\left(Y^{2}\right) 0 ≤ E ( Z 2 ) = a 2 E ( X 2 ) − 2 a b E ( X Y ) + b 2 E ( Y 2 )
不妨设 b ≠ 0 b\neq 0 b = 0 a a a
E ( X Y ) 2 − E ( X 2 ) E ( Y 2 ) ≤ 0 \mathbb{E}(X Y)^{2}-\mathbb{E}\left(X^{2}\right) \mathbb{E}\left(Y^{2}\right) \leq 0 E ( X Y ) 2 − E ( X 2 ) E ( Y 2 ) ≤ 0
当等号成立时,
E ( Z 2 ) = E ( ( a X − b Y ) 2 ) = 0 \mathbb{E}(Z^{2})=\mathbb{E}\left((a X-b Y)^{2}\right)=0 E ( Z 2 ) = E ( ( a X − b Y ) 2 ) = 0
因此 a X − b Y = 0 aX-bY=0 a X − b Y = 0 a , b ∈ R a,b\in \mathbb{R} a , b ∈ R P ( a X = b Y ) = 1 \mathbb{P}(aX=bY)=1 P ( a X = b Y ) = 1
Lemma 7. 相关系数 ρ \rho ρ ∣ ρ ( X , Y ) ∣ ≤ 1 |\rho(X, Y)| \leq 1 ∣ ρ ( X , Y ) ∣ ≤ 1 P ( a X + b Y = c ) = 1 \mathbb{P}(a X+b Y=c)=1 P ( a X + b Y = c ) = 1 a , b , c ∈ R a,b,c\in\mathbb{R} a , b , c ∈ R
证明:对于随机变量 X − E X X-\mathbb{E} X X − E X Y − E Y Y-\mathbb{E} Y Y − E Y
cov 2 ( X , Y ) = E 2 ( ( X − E X ) ( Y − E Y ) ) ≤ E ( ( X − E X ) 2 ) E ( ( Y − E Y ) 2 ) = var ( X ) cov ( Y ) \begin{aligned}
\operatorname{cov}^{2}(X,Y)&=\mathbb{E}^{2}((X-\mathbb{E}X)(Y-\mathbb{E}Y))\\
&\leq \mathbb{E}((X-\mathbb{E}X)^2)\mathbb{E}((Y-\mathbb{E}Y)^2)\\
&=\operatorname{var}(X)\operatorname{cov}(Y)
\end{aligned} c o v 2 ( X , Y ) = E 2 ( ( X − E X ) ( Y − E Y ) ) ≤ E ( ( X − E X ) 2 ) E ( ( Y − E Y ) 2 ) = v a r ( X ) c o v ( Y )
根据相关系数的定义即可证明不等式,当等号成立时
a ( X − E X ) + b ( Y − E Y ) = 0 a(X-\mathbb{E}X)+b(Y-\mathbb{E}Y)=0 a ( X − E X ) + b ( Y − E Y ) = 0
a X − b Y = b E Y − a E X aX-bY=b\mathbb{E}Y-a\mathbb{E}X a X − b Y = b E Y − a E X
令 c = b E Y − a E X c=b\mathbb{E}Y-a\mathbb{E}X c = b E Y − a E X
Example 8. 设随机变量 X , Y X,Y X , Y { 1 , 2 , 3 } , { − 1 , 0 , 2 } \{1,2,3\},\{-1,0,2\} { 1 , 2 , 3 } , { − 1 , 0 , 2 } f ( x , y ) f(x,y) f ( x , y )
经过计算,我们可以得到如下结果:
E ( X Y ) = ∑ x , y x y f ( x , y ) = 29 18 E ( X ) = ∑ x x f X ( x ) = 37 18 , E ( Y ) = 13 18 var ( X ) = E ( X 2 ) − E ( X ) 2 = 233 324 , var ( Y ) = 461 324 cov ( X , Y ) = 41 324 , ρ ( X , Y ) = 41 107413 \begin{aligned}
\mathbb{E}(X Y) &=\sum_{x, y} x y f(x, y)=\frac{29}{18} \\
\mathbb{E}(X) &=\sum_{x} x f_{X}(x)=\frac{37}{18}, \quad \mathbb{E}(Y)=\frac{13}{18} \\
\operatorname{var}(X) &=\mathbb{E}\left(X^{2}\right)-\mathbb{E}(X)^{2}=\frac{233}{324}, \quad \operatorname{var}(Y)=\frac{461}{324} \\
\operatorname{cov}(X, Y) &=\frac{41}{324}, \quad \rho(X, Y)=\frac{41}{\sqrt{107413}}
\end{aligned} E ( X Y ) E ( X ) v a r ( X ) c o v ( X , Y ) = x , y ∑ x y f ( x , y ) = 1 8 2 9 = x ∑ x f X ( x ) = 1 8 3 7 , E ( Y ) = 1 8 1 3 = E ( X 2 ) − E ( X ) 2 = 3 2 4 2 3 3 , v a r ( Y ) = 3 2 4 4 6 1 = 3 2 4 4 1 , ρ ( X , Y ) = 1 0 7 4 1 3 4 1
Exercise 9. 设离散型随机变量 X , Y X,Y X , Y f ( x , y ) = C ( x + y − 1 ) ( x + y ) ( x + y + 1 ) , x , y = 1 , 2 , 3 , … f(x, y)=\frac{C}{(x+y-1)(x+y)(x+y+1)}, \quad x, y=1,2,3, \ldots f ( x , y ) = ( x + y − 1 ) ( x + y ) ( x + y + 1 ) C , x , y = 1 , 2 , 3 , … X , Y X,Y X , Y C C C X , Y X,Y X , Y
难度:★★☆☆☆(点击查看答案) 随机变量 X X X f X ( x ) f_{X}(x) f X ( x )
P ( X = x ) = ∑ y = 1 ∞ P ( X = x , Y = y ) = ∑ y = 1 ∞ C 2 { 1 ( x + y − 1 ) ( x + y ) − 1 ( x + y ) ( x + y + 1 ) } = C 2 x ( x + 1 ) = C 2 ( 1 x − 1 x + 1 ) \begin{aligned}
\mathbb{P}(X=x) &=\sum_{y=1}^{\infty} \mathbb{P}(X=x, Y=y) \\
&=\sum_{y=1}^{\infty} \frac{C}{2}\left\{\frac{1}{(x+y-1)(x+y)}-\frac{1}{(x+y)(x+y+1)}\right\} \\
&=\frac{C}{2 x(x+1)}=\frac{C}{2}\left(\frac{1}{x}-\frac{1}{x+1}\right)
\end{aligned} P ( X = x ) = y = 1 ∑ ∞ P ( X = x , Y = y ) = y = 1 ∑ ∞ 2 C { ( x + y − 1 ) ( x + y ) 1 − ( x + y ) ( x + y + 1 ) 1 } = 2 x ( x + 1 ) C = 2 C ( x 1 − x + 1 1 )
根据 ∑ x = 1 ∞ f X ( x ) = 1 \sum_{x=1}^{\infty}f_{X}(x)=1 ∑ x = 1 ∞ f X ( x ) = 1 C = 2 C=2 C = 2
注意到 f ( x , y ) f(x,y) f ( x , y ) x , y x,y x , y Y Y Y X X X
E ( X ) = ∑ x = 1 ∞ ( x + 1 ) − 1 = ∞ \mathbb{E}(X)=\sum_{x=1}^{\infty}(x+1)^{-1}=\infty E ( X ) = x = 1 ∑ ∞ ( x + 1 ) − 1 = ∞
X , Y X,Y X , Y
Exercise 10. 设离散型随机变量 X , Y X,Y X , Y 0 0 0 1 1 1 ρ \rho ρ E ( max { X 2 , Y 2 } ) ≤ 1 + 1 − ρ 2 \mathbb{E}\left(\max \left\{X^{2}, Y^{2}\right\}\right) \leq 1+\sqrt{1-\rho^{2}} E ( max { X 2 , Y 2 } ) ≤ 1 + 1 − ρ 2
难度:★★★☆☆(点击查看答案) 我们知道 max { u , v } = 1 2 ( u + v ) + 1 2 ∣ u − v ∣ \operatorname{max}\{u, v\}=\frac{1}{2}(u+v)+\frac{1}{2} |u-v| m a x { u , v } = 2 1 ( u + v ) + 2 1 ∣ u − v ∣
E ( max { X 2 , Y 2 } ) = 1 2 E ( X 2 + Y 2 ) + 1 2 E ∣ ( X − Y ) ( X + Y ) ∣ = 1 + 1 2 E ∣ ( X − Y ) ( X + Y ) ∣ \begin{aligned}
\mathbb{E}\left(\max \left\{X^{2}, Y^{2}\right\}\right) &=\frac{1}{2} \mathbb{E}\left(X^{2}+Y^{2}\right)+\frac{1}{2} \mathbb{E}|(X-Y)(X+Y)| \\
&=1+\frac{1}{2} \mathbb{E}|(X-Y)(X+Y)|
\end{aligned} E ( max { X 2 , Y 2 } ) = 2 1 E ( X 2 + Y 2 ) + 2 1 E ∣ ( X − Y ) ( X + Y ) ∣ = 1 + 2 1 E ∣ ( X − Y ) ( X + Y ) ∣
接下来我们需要处理乘积绝对值的期望,把柯西-施瓦茨不等式两边开方得到
∣ E ( X Y ) ∣ ≤ E ( X 2 ) E ( Y 2 ) |\mathbb{E}(XY)|\leq \sqrt{\mathbb{E}(X^{2})\mathbb{E}(Y^{2})} ∣ E ( X Y ) ∣ ≤ E ( X 2 ) E ( Y 2 )
代入得到
E ( max { X 2 , Y 2 } ) ≤ 1 + 1 2 E ( ( X − Y ) 2 ) E ( ( X + Y ) 2 ) = 1 + 1 2 ( 2 − 2 ρ ) ( 2 + 2 ρ ) = 1 + 1 − ρ 2 \begin{aligned}
\mathbb{E}\left(\max \left\{X^{2}, Y^{2}\right\}\right) &\leq 1+\frac{1}{2} \sqrt{\mathbb{E}\left((X-Y)^{2}\right) \mathbb{E}\left((X+Y)^{2}\right)} \\
&=1+\frac{1}{2} \sqrt{(2-2 \rho)(2+2 \rho)}\\
&=1+\sqrt{1-\rho^{2}}
\end{aligned} E ( max { X 2 , Y 2 } ) ≤ 1 + 2 1 E ( ( X − Y ) 2 ) E ( ( X + Y ) 2 ) = 1 + 2 1 ( 2 − 2 ρ ) ( 2 + 2 ρ ) = 1 + 1 − ρ 2
Exercise 11. Mutual information(互信息). 设离散型随机变量 X , Y X,Y X , Y f f f E ( log f X ( X ) ) ≥ E ( log f Y ( X ) ) \mathbb{E}\left(\log f_{X}(X)\right) \geq \mathbb{E}\left(\log f_{Y}(X)\right) E ( log f X ( X ) ) ≥ E ( log f Y ( X ) ) I = E ( log { f ( X , Y ) f X ( X ) f Y ( Y ) } ) ≥ 0 I=\mathbb{E}\left(\log \left\{\frac{f(X, Y)}{f_{X}(X) f_{Y}(Y)}\right\}\right)\geq 0 I = E ( log { f X ( X ) f Y ( Y ) f ( X , Y ) } ) ≥ 0 X , Y X,Y X , Y
难度:★★★☆☆(点击查看答案) (1)我们知道 log y ≤ y − 1 \log{y}\leq y-1 log y ≤ y − 1 y = 1 y=1 y = 1
E ( log f Y ( X ) f X ( X ) ) ≤ E [ f Y ( X ) f X ( X ) ] − 1 = ∑ x f X ( x ) f Y ( x ) f X ( x ) − 1 = ∑ x f Y ( x ) − 1 ≤ 0 \begin{aligned}
\mathbb{E}\left(\log \frac{f_{Y}(X)}{f_{X}(X)}\right) &\leq \mathbb{E}\left[\frac{f_{Y}(X)}{f_{X}(X)}\right]-1\\
&=\sum_{x}f_{X}(x)\frac{f_{Y}(x)}{f_{X}(x)}-1\\
&=\sum_{x}f_{Y}(x)-1\leq 0
\end{aligned} E ( log f X ( X ) f Y ( X ) ) ≤ E [ f X ( X ) f Y ( X ) ] − 1 = x ∑ f X ( x ) f X ( x ) f Y ( x ) − 1 = x ∑ f Y ( x ) − 1 ≤ 0
等号成立当且仅当 f X = f Y f_{X}=f_{Y} f X = f Y
(2)还是利用 log y ≤ y − 1 \log{y}\leq y-1 log y ≤ y − 1
E ( log { f X ( X ) f Y ( Y ) f ( X , Y ) } ) ≤ E ( f X ( X ) f Y ( Y ) f ( X , Y ) ) − 1 = ∑ x , y f ( x , y ) f X ( x ) f Y ( y ) f ( x , y ) − 1 = ∑ x f X ( x ) ∑ y f Y ( y ) − 1 = 0 \begin{aligned}
\mathbb{E}\left(\log \left\{\frac{f_{X}(X) f_{Y}(Y)}{f(X, Y)}\right\}\right)&\leq \mathbb{E}\left(\frac{f_{X}(X) f_{Y}(Y)}{f(X, Y)}\right)-1\\
&=\sum_{x,y}f(x,y)\frac{f_{X}(x)f_{Y}(y)}{f(x,y)}-1\\
&=\sum_{x}f_{X}(x)\sum_{y}f_{Y}(y)-1=0
\end{aligned} E ( log { f ( X , Y ) f X ( X ) f Y ( Y ) } ) ≤ E ( f ( X , Y ) f X ( X ) f Y ( Y ) ) − 1 = x , y ∑ f ( x , y ) f ( x , y ) f X ( x ) f Y ( y ) − 1 = x ∑ f X ( x ) y ∑ f Y ( y ) − 1 = 0
等号成立当且仅当 f ( x , y ) = f X ( x ) f Y ( y ) f(x,y)=f_{X}(x)f_{Y}(y) f ( x , y ) = f X ( x ) f Y ( y ) X , Y X,Y X , Y
之前我们讨论了条件概率 P ( B ∣ A ) \mathbb{P}(B \mid A) P ( B ∣ A ) Y Y Y X X X
Definition 1. 随机变量 Y Y Y X = x X=x X = x conditional distribution function(条件分布函数) F Y ∣ X ( ⋅ ∣ x ) F_{Y \mid X}(\cdot \mid x) F Y ∣ X ( ⋅ ∣ x ) F Y ∣ X ( y ∣ x ) = P ( Y ≤ y ∣ X = x ) F_{Y \mid X}(y \mid x)=\mathbb{P}(Y \leq y \mid X=x) F Y ∣ X ( y ∣ x ) = P ( Y ≤ y ∣ X = x ) P ( X = x ) > 0 \mathbb{P}(X=x)>0 P ( X = x ) > 0 conditional mass function(条件质量函数) f Y ∣ X ( ⋅ ∣ x ) f_{Y \mid X}(\cdot \mid x) f Y ∣ X ( ⋅ ∣ x ) f Y ∣ X ( y ∣ x ) = P ( Y = y ∣ X = x ) f_{Y \mid X}(y \mid x)=\mathbb{P}(Y=y \mid X=x) f Y ∣ X ( y ∣ x ) = P ( Y = y ∣ X = x )
根据定义我们可以得到
f Y ∣ X ( y ∣ x ) = P ( Y = y ∣ X = x ) = P ( Y = y , X = x ) P ( X = x ) = f X , Y ( x , y ) f X ( x ) \begin{aligned}
f_{Y \mid X}(y \mid x)
&=\mathbb{P}(Y=y \mid X=x)\\
&=\frac{\mathbb{P}(Y=y, X=x)}{\mathbb{P}(X=x)}=\frac{f_{X,Y}(x,y)}{f_{X}(x)}
\end{aligned} f Y ∣ X ( y ∣ x ) = P ( Y = y ∣ X = x ) = P ( X = x ) P ( Y = y , X = x ) = f X ( x ) f X , Y ( x , y )
由此可知,当 f Y ∣ X = f Y f_{Y \mid X}=f_{Y} f Y ∣ X = f Y X , Y X,Y X , Y
当给定 X = x X=x X = x Y Y Y f Y ∣ X ( y ∣ x ) f_{Y \mid X}(y \mid x) f Y ∣ X ( y ∣ x ) y y y
∑ y y f Y ∣ X ( y ∣ x ) \sum_{y} y f_{Y \mid X}(y \mid x) y ∑ y f Y ∣ X ( y ∣ x )
命名为 conditional expectation(条件期望) ,当 x x x
ψ ( x ) = E ( Y ∣ X = x ) = ∑ y y f Y ∣ X ( y ∣ x ) \psi(x)=\mathbb{E}(Y \mid X=x)=\sum_{y} y f_{Y \mid X}(y \mid x) ψ ( x ) = E ( Y ∣ X = x ) = y ∑ y f Y ∣ X ( y ∣ x )
Definition 2. 记 ψ ( x ) = E ( Y ∣ X = x ) \psi(x)=\mathbb{E}(Y \mid X=x) ψ ( x ) = E ( Y ∣ X = x ) Y Y Y X X X E ( Y ∣ X ) = ψ ( X ) \mathbb{E}(Y \mid X)=\psi(X) E ( Y ∣ X ) = ψ ( X )
虽然条件期望听起来像是一个数值,但实际上是一个与 X X X
且条件期望拥有下面这一条重要性质。
Theorem 3. 条件期望 ψ ( X ) = E ( Y ∣ X ) \psi(X)=\mathbb{E}(Y \mid X) ψ ( X ) = E ( Y ∣ X ) E ( ψ ( X ) ) = E ( Y ) \mathbb{E}(\psi(X))=\mathbb{E}(Y) E ( ψ ( X ) ) = E ( Y )
证明:根据 Lemmma 3.3.3
E ( ψ ( X ) ) = ∑ x ψ ( x ) f X ( x ) = ∑ x , y y f Y ∣ X ( y ∣ x ) f X ( x ) = ∑ x , y y f X , Y ( x , y ) = ∑ y y f Y ( y ) = E ( Y ) \begin{aligned}
\mathbb{E}(\psi(X)) &=\sum_{x} \psi(x) f_{X}(x)=\sum_{x, y} y f_{Y \mid X}(y \mid x) f_{X}(x) \\
&=\sum_{x, y} y f_{X, Y}(x, y)=\sum_{y} y f_{Y}(y)=\mathbb{E}(Y)
\end{aligned} E ( ψ ( X ) ) = x ∑ ψ ( x ) f X ( x ) = x , y ∑ y f Y ∣ X ( y ∣ x ) f X ( x ) = x , y ∑ y f X , Y ( x , y ) = y ∑ y f Y ( y ) = E ( Y )
这个性质非常的重要,它提供了一种计算期望 E ( Y ) \mathbb{E}(Y) E ( Y )
E ( Y ) = ∑ x E ( Y ∣ X = x ) P ( X = x ) \mathbb{E}(Y)=\sum_{x} \mathbb{E}(Y \mid X=x) \mathbb{P}(X=x) E ( Y ) = x ∑ E ( Y ∣ X = x ) P ( X = x )
Example 4. 一只母鸡下了 N N N N N N λ \lambda λ p p p K K K E ( K ∣ N ) , E ( K ) , E ( N ∣ K ) \mathbb{E}(K \mid N), \mathbb{E}(K),\mathbb{E}(N \mid K) E ( K ∣ N ) , E ( K ) , E ( N ∣ K )
我们知道泊松分布的质量函数
f N ( n ) = λ n n ! e − λ f_{N}(n)=\frac{\lambda^{n}}{n !} e^{-\lambda} f N ( n ) = n ! λ n e − λ
根据二项分布可以得到 K K K N N N
f K ∣ N ( k ∣ n ) = ( n k ) p k ( 1 − p ) n − k f_{K \mid N}(k \mid n)=\binom{n}{k} p^{k}(1-p)^{n-k} f K ∣ N ( k ∣ n ) = ( k n ) p k ( 1 − p ) n − k
由此可以计算
ψ ( n ) = E ( K ∣ N = n ) = ∑ k k f K ∣ N ( k ∣ n ) = p n \psi(n)=\mathbb{E}(K \mid N=n)=\sum_{k} k f_{K \mid N}(k \mid n)=p n ψ ( n ) = E ( K ∣ N = n ) = k ∑ k f K ∣ N ( k ∣ n ) = p n
E ( K ∣ N ) = ψ ( N ) = p N \mathbb{E}(K \mid N)=\psi(N)=p N E ( K ∣ N ) = ψ ( N ) = p N
根据 Theorem 3 可得
E ( K ) = E ( ψ ( N ) ) = p E ( N ) = p λ \mathbb{E}(K)=\mathbb{E}(\psi(N))=p \mathbb{E}(N)=p \lambda E ( K ) = E ( ψ ( N ) ) = p E ( N ) = p λ
接下来要求 E ( N ∣ K ) \mathbb{E}(N \mid K) E ( N ∣ K ) f N ∣ K f_{N \mid K} f N ∣ K
f N ∣ K ( n ∣ k ) = P ( N = n ∣ K = k ) = P ( K = k , N = n ) P ( K = k ) = f N , K f K \begin{aligned}
f_{N \mid K}(n \mid k) &=\mathbb{P}(N=n \mid K=k) \\
&=\frac{\mathbb{P}(K=k, N=n) }{\mathbb{P}(K=k)}=\frac{f_{N,K}}{f_{K}}
\end{aligned} f N ∣ K ( n ∣ k ) = P ( N = n ∣ K = k ) = P ( K = k ) P ( K = k , N = n ) = f K f N , K
因此我们需要先求联合质量函数
f N , K ( n , k ) = f K ∣ N ( k ∣ n ) f N ( n ) = ( n k ) p k ( 1 − p ) n − k λ n n ! e − λ f_{N,K}(n,k)=f_{K \mid N}(k \mid n)f_{N}(n)=\binom{n}{k} p^{k}(1-p)^{n-k}\frac{\lambda^n}{n!} e^{-\lambda} f N , K ( n , k ) = f K ∣ N ( k ∣ n ) f N ( n ) = ( k n ) p k ( 1 − p ) n − k n ! λ n e − λ
以及 K K K
f K ( k ) = ∑ n = k ∞ ( n k ) p k ( 1 − p ) n − k λ n n ! e − λ = p k k ! e − λ ∑ n = k ∞ ( 1 − p ) n − k ( n − k ) ! λ n = p k k ! e − λ ∑ n = 0 ∞ ( 1 − p ) n n ! λ n + k = p k k ! e − λ λ k ∑ n = 0 ∞ [ ( 1 − p ) λ ] n n ! = p k k ! e − λ λ k e ( 1 − p ) λ = ( λ p ) k e − p λ k ! \begin{aligned}f_{K}(k)
&=\sum_{n=k}^{\infty} \binom{n}{k} p^{k}(1-p)^{n-k}\frac{\lambda^n}{n!} e^{-\lambda}=\frac{p^{k}}{k!}e^{-\lambda}\sum_{n=k}^{\infty} \frac{(1-p)^{n-k}}{(n-k)!} \lambda^n\\
&=\frac{p^{k}}{k!}e^{-\lambda}\sum_{n=0}^{\infty} \frac{(1-p)^{n}}{n!} \lambda^{n+k}=\frac{p^{k}}{k!}e^{-\lambda}\lambda^{k}\sum_{n=0}^{\infty} \frac{[(1-p)\lambda]^{n}}{n!}\\
&=\frac{p^{k}}{k!}e^{-\lambda}\lambda^{k}e^{(1-p)\lambda}=\frac{(\lambda p)^{k}e^{-p\lambda}}{k!}
\end{aligned} f K ( k ) = n = k ∑ ∞ ( k n ) p k ( 1 − p ) n − k n ! λ n e − λ = k ! p k e − λ n = k ∑ ∞ ( n − k ) ! ( 1 − p ) n − k λ n = k ! p k e − λ n = 0 ∑ ∞ n ! ( 1 − p ) n λ n + k = k ! p k e − λ λ k n = 0 ∑ ∞ n ! [ ( 1 − p ) λ ] n = k ! p k e − λ λ k e ( 1 − p ) λ = k ! ( λ p ) k e − p λ
由此得到
f N ∣ K ( n ∣ k ) = f N , K f K = [ ( 1 − p ) λ ] n − k ( n − k ) ! e − ( 1 − p ) λ f_{N \mid K}(n \mid k)=\frac{f_{N,K}}{f_{K}}=\frac{[(1-p)\lambda]^{n-k}}{(n-k)!}e^{-(1-p)\lambda} f N ∣ K ( n ∣ k ) = f K f N , K = ( n − k ) ! [ ( 1 − p ) λ ] n − k e − ( 1 − p ) λ
因此
ψ ( k ) = E ( N ∣ K = k ) = ∑ n = k ∞ n f N ∣ K ( n ∣ k ) = e − ( 1 − p ) λ ∑ n = 0 ∞ ( n + k ) [ ( 1 − p ) λ ] n n ! = k + ( 1 − p ) λ \begin{aligned}\psi(k)
&=\mathbb{E}(N \mid K=k)=\sum_{n=k}^{\infty}nf_{N \mid K}(n \mid k)\\
&=e^{-(1-p)\lambda}\sum_{n=0}^{\infty}(n+k)\frac{[(1-p)\lambda]^{n}}{n!}=k+(1-p)\lambda
\end{aligned} ψ ( k ) = E ( N ∣ K = k ) = n = k ∑ ∞ n f N ∣ K ( n ∣ k ) = e − ( 1 − p ) λ n = 0 ∑ ∞ ( n + k ) n ! [ ( 1 − p ) λ ] n = k + ( 1 − p ) λ
即 E ( N ∣ K ) = K + ( 1 − p ) λ \mathbb{E}(N \mid K)=K+(1-p)\lambda E ( N ∣ K ) = K + ( 1 − p ) λ
Theorem 5. 条件期望 ψ ( X ) = E ( Y ∣ X ) \psi(X)=\mathbb{E}(Y \mid X) ψ ( X ) = E ( Y ∣ X ) E ( ψ ( X ) g ( X ) ) = E ( Y g ( X ) ) \mathbb{E}(\psi(X) g(X))=\mathbb{E}(Y g(X)) E ( ψ ( X ) g ( X ) ) = E ( Y g ( X ) ) g ( X ) g(X) g ( X )
证明:和 Theorem 3 类似
E ( ψ ( X ) g ( X ) ) = ∑ x ψ ( x ) g ( x ) f X ( x ) = ∑ x , y y g ( x ) f Y ∣ X ( y ∣ x ) f X ( x ) = ∑ x , y y g ( x ) f X , Y ( x , y ) = E ( Y g ( X ) ) \begin{aligned}
\mathbb{E}(\psi(X) g(X)) &=\sum_{x} \psi(x) g(x) f_{X}(x)=\sum_{x, y} y g(x) f_{Y \mid X}(y \mid x) f_{X}(x) \\
&=\sum_{x, y} y g(x) f_{X, Y}(x, y)=\mathbb{E}(Y g(X))
\end{aligned} E ( ψ ( X ) g ( X ) ) = x ∑ ψ ( x ) g ( x ) f X ( x ) = x , y ∑ y g ( x ) f Y ∣ X ( y ∣ x ) f X ( x ) = x , y ∑ y g ( x ) f X , Y ( x , y ) = E ( Y g ( X ) )
事实上,令 g ( x ) = 1 g(x)=1 g ( x ) = 1 Theorem 3 ,该定理将其进行了扩展。
8、Sums of random variables(随机变量的和) 在概率论中,我们常常要考虑随机变量之和的分布,例如我们已经见过的投掷 n n n
然而还有很多情形更为复杂,我们需要一个系统的理论在解决随机变量之和的问题。
Theorem 1. 我们有 P ( X + Y = z ) = ∑ f ( x , z − x ) \mathbb{P}(X+Y=z)=\sum f(x, z-x) P ( X + Y = z ) = ∑ f ( x , z − x )
证明是显然的
P ( X + Y = z ) = ∑ x P ( X = x , Y = z − x ) = ∑ x f ( x , z − x ) \mathbb{P}(X+Y=z)=\sum_{x} \mathbb{P}(X=x, Y=z-x)=\sum_{x} f(x, z-x) P ( X + Y = z ) = x ∑ P ( X = x , Y = z − x ) = x ∑ f ( x , z − x )
特别的,如果 X , Y X,Y X , Y
P ( X + Y = z ) = f X + Y ( z ) = ∑ x f X ( x ) f Y ( z − x ) \mathbb{P}(X+Y=z)=f_{X+Y}(z)=\sum_{x} f_{X}(x) f_{Y}(z-x) P ( X + Y = z ) = f X + Y ( z ) = x ∑ f X ( x ) f Y ( z − x )
其中 X + Y X+Y X + Y X , Y X,Y X , Y convolution(卷积) ,记作
f X + Y = f X ∗ f Y f_{X+Y}=f_{X} * f_{Y} f X + Y = f X ∗ f Y
Example 2. 设随机变量 X 1 , X 2 X_{1},X_{2} X 1 , X 2 f ( k ) = p ( 1 − p ) k − 1 , k = 1 , 2 , … f(k)=p(1-p)^{k-1}, \quad k=1,2, \ldots f ( k ) = p ( 1 − p ) k − 1 , k = 1 , 2 , … Z = X 1 + X 2 Z=X_{1}+X_{2} Z = X 1 + X 2
P ( Z = z ) = ∑ k P ( X 1 = k ) P ( X 2 = z − k ) = ∑ k = 1 z − 1 p ( 1 − p ) k − 1 p ( 1 − p ) z − k − 1 = ( z − 1 ) p 2 ( 1 − p ) z − 2 , z = 2 , 3 , … \begin{aligned}
\mathbb{P}(Z=z) &=\sum_{k} \mathbb{P}\left(X_{1}=k\right) \mathbb{P}\left(X_{2}=z-k\right) \\
&=\sum_{k=1}^{z-1} p(1-p)^{k-1} p(1-p)^{z-k-1} \\
&=(z-1) p^{2}(1-p)^{z-2}, \quad z=2,3, \ldots
\end{aligned} P ( Z = z ) = k ∑ P ( X 1 = k ) P ( X 2 = z − k ) = k = 1 ∑ z − 1 p ( 1 − p ) k − 1 p ( 1 − p ) z − k − 1 = ( z − 1 ) p 2 ( 1 − p ) z − 2 , z = 2 , 3 , …
Example 3. Pepys's problem(佩皮斯问题). Sam 扔了 6 n 6n 6 n n n n 6 6 6 Isaac 扔了 6 ( n + 1 ) 6(n+1) 6 ( n + 1 ) n + 1 n+1 n + 1 6 6 6
设随机变量 X n X_{n} X n 6 n 6n 6 n 6 6 6
X n + 1 = X n + Y X_{n+1}=X_{n}+Y X n + 1 = X n + Y
其中 Y Y Y X 1 X_{1} X 1 X n X_{n} X n
P ( X n + 1 ≥ n + 1 ) = ∑ r = 0 6 P ( X n ≥ n + 1 − r ) P ( Y = r ) = P ( X n ≥ n ) + ∑ r = 0 6 [ P ( X n ≥ n + 1 − r ) − P ( X n ≥ n ) ] P ( Y = r ) \begin{aligned}
\mathbb{P}\left(X_{n+1} \geq n+1\right) &=\sum_{r=0}^{6} \mathbb{P}\left(X_{n} \geq n+1-r\right) \mathbb{P}(Y=r) \\
&=\mathbb{P}\left(X_{n} \geq n\right)+\sum_{r=0}^{6}\left[\mathbb{P}\left(X_{n} \geq n+1-r\right)-\mathbb{P}\left(X_{n} \geq n\right)\right] \mathbb{P}(Y=r)
\end{aligned} P ( X n + 1 ≥ n + 1 ) = r = 0 ∑ 6 P ( X n ≥ n + 1 − r ) P ( Y = r ) = P ( X n ≥ n ) + r = 0 ∑ 6 [ P ( X n ≥ n + 1 − r ) − P ( X n ≥ n ) ] P ( Y = r )
设 g ( k ) = P ( X n = k ) g(k)=\mathbb{P}\left(X_{n}=k\right) g ( k ) = P ( X n = k ) g ( k ) g(k) g ( k )
P ( X n + 1 ≥ n + 1 ) = P ( X n ≥ n ) + P ( Y = 0 ) ( − g ( n ) ) + ∑ r = 1 6 ∑ k = n − r + 1 n − 1 g ( k ) P ( Y = r ) ≤ P ( X n ≥ n ) + P ( Y = 0 ) ( − g ( n ) ) + ∑ r = 1 6 ( r − 1 ) g ( n ) P ( Y = r ) = P ( X n ≥ n ) + g ( n ) ∑ r = 0 6 ( r − 1 ) P ( Y = r ) = P ( X n ≥ n ) + g ( n ) ( E ( Y ) − 1 ) \begin{aligned}
\mathbb{P}\left(X_{n+1} \geq n+1\right)
&=\mathbb{P}\left(X_{n} \geq n\right)+\mathbb{P}(Y=0)(-g(n))+\sum_{r=1}^{6}\sum_{k=n-r+1}^{n-1}g(k)\mathbb{P}(Y=r)\\
&\leq \mathbb{P}\left(X_{n} \geq n\right)+\mathbb{P}(Y=0)(-g(n))+\sum_{r=1}^{6}(r-1)g(n)\mathbb{P}(Y=r)\\
&=\mathbb{P}\left(X_{n} \geq n\right)+g(n) \sum_{r=0}^{6}(r-1) \mathbb{P}(Y=r)\\
&=\mathbb{P}\left(X_{n} \geq n\right)+g(n)(\mathbb{E}(Y)-1)
\end{aligned} P ( X n + 1 ≥ n + 1 ) = P ( X n ≥ n ) + P ( Y = 0 ) ( − g ( n ) ) + r = 1 ∑ 6 k = n − r + 1 ∑ n − 1 g ( k ) P ( Y = r ) ≤ P ( X n ≥ n ) + P ( Y = 0 ) ( − g ( n ) ) + r = 1 ∑ 6 ( r − 1 ) g ( n ) P ( Y = r ) = P ( X n ≥ n ) + g ( n ) r = 0 ∑ 6 ( r − 1 ) P ( Y = r ) = P ( X n ≥ n ) + g ( n ) ( E ( Y ) − 1 )
显然 E ( Y ) = 1 \mathbb{E}(Y)=1 E ( Y ) = 1 Sam 更容易。